Edit1: I have collected most of the delay related functions and variables to a DelayLayer class. Applied surrogate update to delays as suggested by (Tomas Fiers, Markus Ghosh and Alessandro Galloni). Method B was applied. The delay is applied only to the first layer. Appling the delay with Method B subtracts a duration=delay_max from the input durection. So every sunsequent push through a layer decreases the duration(or effective duration). So, for applying multiple delay layers, the duration of the inputs needs to be appended with delay_max*number_delay_layer.
I will start with the concept as shown in the below figure.
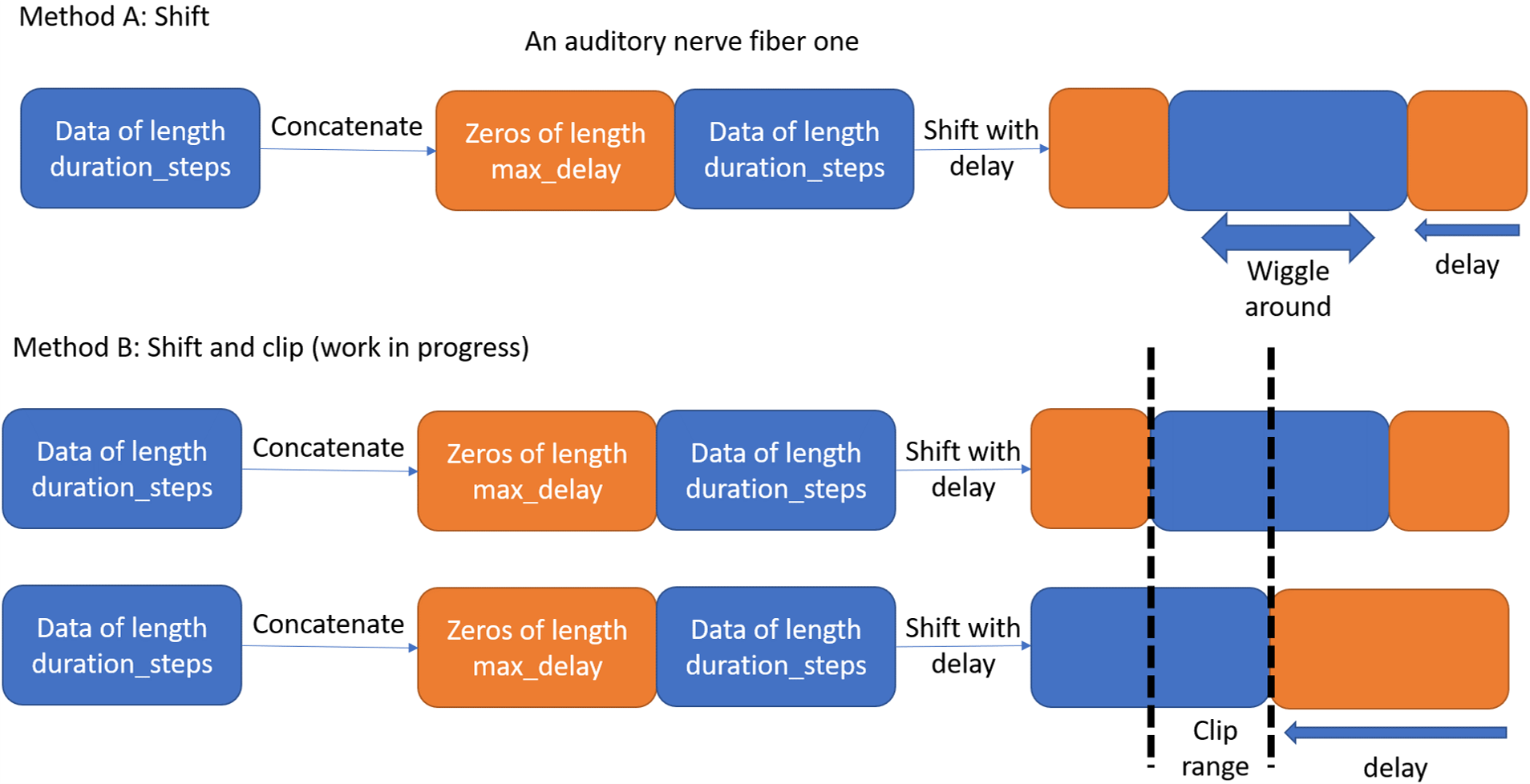
Method A: the aim is to pad the output spikes with a tensor of zeros then apply a delay. This will shift the spikes as shown in the figure, then the data will be surronded by zeros from both sides. However, this method will lead to misalignment between different anfs as some fibers will have the zero pad while others data at the same time point, which is not the case we expect. A possible solution is to clib the data as shown in Method B. I think, this will solve the problem, but will use a larger duration_steps.
A way to implement this is shown below in the code. I think, this is not the only way and there is a paper that implemented the delays differently with a dedicated module: https://
Here is my thoughts on the topic if anyone is interested, if not, it is skippable :). I think, delays (given they have sufficient resolution) in their essence, and for the first layer, are a transformer from the time domain to the spatial domain. For a fixed duration_steps and after application of delays, all information is avilable in the first layer to do any computation on the information in this step. To learn far away concepts in the time domain, we either increase the max delays range in the first layer or apply a RNN.
#@title Imports
import os
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.gridspec import GridSpec
import torch
import torch.nn as nn
import torch.nn.functional as F
dtype = torch.float
# Check whether a GPU is available
if torch.cuda.is_available():
device = torch.device("cuda")
else:
device = torch.device("cpu")
my_computer_is_slow = True # set this to True if using Colab
torch.set_printoptions(precision=1, sci_mode=False)
np.set_printoptions(precision=1, suppress=True)Comment #1 If we set the no_phase_delays flag to ‘True’, some how the network learns and the loss is reduced. It is not as good as with phase_delays. I just find it weird. I think, it might be good to decouple and the study the effects of weights and delays separately. Edit 1: it seems that, training weights has more salience than delays.
#@title Input functions
# Not using Brian so we just use these constants to make equations look nicer below
second = 1
ms = 1e-3
Hz = 1
# Stimulus and simulation parameters
dt = 1*ms # large time step to make simulations run faster for tutorial
anf_per_ear = 100 # repeats of each ear with independent noise
envelope_power = 2 # higher values make sharper envelopes, easier
rate_max = 600*Hz # maximum Poisson firing rate
f = 20*Hz # stimulus frequency
duration = .15*second # stimulus duration
duration_steps = int(np.round(duration/dt))
input_size = 2*anf_per_ear
"""Delay related flags"""
trainable_delays, no_phase_delays =True, True
""""""
# Generate an input signal (spike array) from array of true IPDs
def input_signal(ipd):
num_samples = len(ipd)
T = np.arange(duration_steps)*dt # array of times
phi = 2*np.pi*(f*T+np.random.rand()) # array of phases corresponding to those times with random offset
# each point in the array will have a different phase based on which ear it is
# and its delay
theta = np.zeros((num_samples, duration_steps, 2*anf_per_ear))
# for each ear, we have anf_per_ear different phase delays from to pi/2 so
# that the differences between the two ears can cover the full range from -pi/2 to pi/2
"""Delay related update"""
if trainable_delays or no_phase_delays:
phase_delays = np.array([0]*anf_per_ear)
else:
phase_delays = np.linspace(0, np.pi/2, anf_per_ear)
""""""
# now we set up these theta to implement that. Some numpy vectorisation logic here which looks a little weird,
# but implements the idea in the text above.
theta[:, :, :anf_per_ear] = phi[np.newaxis, :, np.newaxis]+phase_delays[np.newaxis, np.newaxis, :]
theta[:, :, anf_per_ear:] = phi[np.newaxis, :, np.newaxis]+phase_delays[np.newaxis, np.newaxis, :]+ipd[:, np.newaxis, np.newaxis]
# now generate Poisson spikes at the given firing rate as in the previous notebook
spikes = np.random.rand(num_samples, duration_steps, 2*anf_per_ear)<rate_max*dt*(0.5*(1+np.sin(theta)))**envelope_power
return spikes
# Generate some true IPDs from U(-pi/2, pi/2) and corresponding spike arrays
def random_ipd_input_signal(num_samples, tensor=True):
ipd = np.random.rand(num_samples)*np.pi-np.pi/2 # uniformly random in (-pi/2, pi/2)
spikes = input_signal(ipd)
if tensor:
ipd = torch.tensor(ipd, device=device, dtype=dtype)
spikes = torch.tensor(spikes, device=device, dtype=dtype)
return ipd, spikesComment #2 The main actors that made the differentiable delay possible are the ‘F.affine_grid’ and ‘F.grid_sample’ functions. They provided ways to shift the delays while keeping the input spike shape and content. These functions are used in spatial transformers. Togther, I think, they make a soft function by interpolating between the indices. Delays are index related and hence they are not differentiable, so these functions are one way of circumventing that.
#@title Delay layer
class DelayLayer(nn.Module):
""" Custom Delay Layer """
def __init__(self, max_delay=50*ms, trainable_delays=True, num_ear=2,
constant_delays=False, constant_value=0, lr_delay=1e-3):
super().__init__()
self.max_delay = max_delay
self.trainable_delays = trainable_delays
self.num_ear = num_ear
self.constant_delays = constant_delays
self.constant_value = constant_value
self.lr_delay = lr_delay # Not fine tuned much, but improves performance on no_delays case
self.effective_duration = duration_steps - int(max_delay/ms)
self.delays_out = self._init_delay_vector()
self.optimizer_delay = self._init_optimizer()
try:
assert duration >= (max_delay-ms)*3
except AssertionError:
print('Duration too short')
assert False
# Delays with constant or random initialisation
# Might think of other ways to initialize delays and their effect on performance
def _init_delay_vector(self):
if self.constant_delays:
delays = torch.nn.parameter.Parameter\
(torch.FloatTensor([self.constant_value*ms]*anf_per_ear*self.num_ear), requires_grad=trainable_delays)
else:
delays_numpy = np.random.randint(dt/ms, high=int(self.max_delay/ms), size=int(anf_per_ear*self.num_ear), dtype=int)*ms
delays = torch.nn.parameter.Parameter(torch.FloatTensor(delays_numpy), requires_grad=trainable_delays)
return delays
def _init_optimizer(self):
optimizer_delay = torch.optim.Adam([self.delays_out], lr=self.lr_delay)
return optimizer_delay
def forward(self, spikes_in):
# Limiting applied delays to the range(0, max_delay)
delays = delay_fn(self.delays_out)
# Expand the dimenion as required by the functions
spikes_in = spikes_in[:, None, :, :]
spikes_size = spikes_in.size()
zero_pad = torch.zeros((spikes_size[0], spikes_size[1], int(self.max_delay/ms), spikes_size[3]))
# Applying the zero pad
spikes_in = torch.cat((zero_pad, spikes_in), 2)
spikes_in = torch.transpose(spikes_in, 0, 3)
spikes_size = spikes_in.size()
batch_size_in, height, width = spikes_size[0], spikes_size[2], spikes_size[3]
# Applying a transformation with only translation
affine_transformation = torch.zeros(batch_size_in, 2, 3)
affine_transformation[:, 0, 0] = 1
affine_transformation[:, 1, 1] = 1
affine_transformation[:, 1, 2] = (2/height)*delays # This is very important: delays have to be whole numbers or they will alter the input spikes values and distribution.
grid = F.affine_grid(affine_transformation, (batch_size_in, 1, height, width), align_corners=False)
# Grid sampling to acquire the shifted spikes
spikes_out = F.grid_sample(spikes_in, grid, align_corners=False)
spikes_out = torch.transpose(spikes_out, 0, 3)
spikes_out = torch.squeeze(spikes_out)
spikes_out = spikes_out[:, int(self.max_delay/ms):duration_steps, :] # Clipping the time series to have matching delays as shown in Method B
return spikes_out
delay_layer = DelayLayer()
delays_out_original = delay_layer.delays_out.clone()#@title Surrogate Gradients
beta = 5
beta_delay = 5
class SurrGradSpike(torch.autograd.Function):
@staticmethod
def forward(ctx, input):
ctx.save_for_backward(input)
out = torch.zeros_like(input)
out[input > 0] = 1.0
return out
@staticmethod
def backward(ctx, grad_output):
input, = ctx.saved_tensors
# Original SPyTorch/SuperSpike gradient
# This seems to be a typo or error? But it works well
#grad = grad_output/(100*torch.abs(input)+1.0)**2
# Sigmoid
grad = grad_output*beta*torch.sigmoid(beta*input)*(1-torch.sigmoid(beta*input))
return grad
spike_fn = SurrGradSpike.apply
class DelayUpdate(torch.autograd.Function):
@staticmethod
def forward(ctx, delays):
ctx.save_for_backward(delays)
delays_forward = torch.round(torch.clip(delays, min=0, max=delay_layer.max_delay-ms)/ms)
return delays_forward
@staticmethod
def backward(ctx, grad_output):
delways_in, = ctx.saved_tensors
delways_in = beta_delay*grad_output*delways_in/ms
return delways_in
delay_fn = DelayUpdate.apply#@title Discretise
# classes at 15 degree increments
num_classes = 180//15
print(f'Number of classes = {num_classes}')
def discretise(ipds):
return ((ipds+np.pi/2)*num_classes/np.pi).long() # assumes input is tensor
def continuise(ipd_indices): # convert indices back to IPD midpoints
return (ipd_indices+0.5)/num_classes*np.pi-np.pi/2Number of classes = 12
#@title Training parameters and data generation
# Parameters for training. These aren't optimal, but instead designed
# to give a reasonable result in a small amount of time for the tutorial!
if my_computer_is_slow:
batch_size = 64
n_training_batches = 64
else:
batch_size = 128
n_training_batches = 128
n_testing_batches = 32
num_samples = batch_size*n_training_batches
# Generator function iterates over the data in batches
# We randomly permute the order of the data to improve learning
def data_generator(ipds, spikes):
perm = torch.randperm(spikes.shape[0])
spikes = spikes[perm, :, :]
ipds = ipds[perm]
n, _, _ = spikes.shape
n_batch = n//batch_size
for i in range(n_batch):
x_local = spikes[i*batch_size:(i+1)*batch_size, :, :]
y_local = ipds[i*batch_size:(i+1)*batch_size]
yield x_local, y_local#@title Weights and the model function (SNN)
num_hidden = 30
# Weights and uniform weight initialisation
def init_weight_matrices():
# Input to hidden layer
W1 = nn.Parameter(torch.empty((input_size, num_hidden), device=device, dtype=dtype), requires_grad=True)
fan_in, _ = nn.init._calculate_fan_in_and_fan_out(W1)
bound = 1 / np.sqrt(fan_in)
nn.init.uniform_(W1, -bound, bound)
# Hidden layer to output
W2 = nn.Parameter(torch.empty((num_hidden, num_classes), device=device, dtype=dtype), requires_grad=True)
fan_in, _ = nn.init._calculate_fan_in_and_fan_out(W2)
bound = 1 / np.sqrt(fan_in)
nn.init.uniform_(W2, -bound, bound)
return W1, W2
# Run the simulation
def snn(input_spikes, W1, W2, tau=5*ms):
"""Delay related update"""
if trainable_delays:
# input_spikes = apply_delays(input_spikes, delays)
input_spikes = delay_layer(input_spikes)
duration_in = delay_layer.effective_duration
else:
duration_in = duration_steps
""""""
# First layer: input to hidden
v = torch.zeros((batch_size, num_hidden), device=device, dtype=dtype)
s = torch.zeros((batch_size, num_hidden), device=device, dtype=dtype)
s_rec = [s]
h = torch.einsum("abc,cd->abd", (input_spikes, W1))
alpha = np.exp(-dt/tau)
"""Delay related update"""
for t in range(duration_in - 1):
new_v = (alpha*v + h[:, t, :])*(1-s) # multiply by 0 after a spike
s = spike_fn(v-1) # threshold of 1
v = new_v
s_rec.append(s)
s_rec = torch.stack(s_rec, dim=1)
# Second layer: hidden to output
v = torch.zeros((batch_size, num_classes), device=device, dtype=dtype)
s = torch.zeros((batch_size, num_classes), device=device, dtype=dtype)
v_rec = [v]
h = torch.einsum("abc,cd->abd", (s_rec, W2))
alpha = np.exp(-dt/tau)
"""Delay related update"""
for t in range(duration_in - 1):
v = alpha*v + h[:, t, :]
v_rec.append(v)
v_rec = torch.stack(v_rec, dim=1)
# Return recorded membrane potential of output
return v_recComment #3 The next issue, after the differntiable delays, is the application of the gradients. The gradients need to be within a reasonable range (a fraction of the maximum delay) and a multiple of the dt (minimum delay). For this reason I used SGD with 0 parameters so that the update is: delays_new = delays_old + lr_delay*gradients. I think a dedicated optimizer might be needed to provide a robust and safe way to apply the gradients to ensure that the updated delays are always whole numbers.
#@title Training
# Training parameters
nb_epochs = 25 # quick, it won't have converged
lr = 0.01 # learning rate
# Generate the training data
ipds, spikes = random_ipd_input_signal(num_samples)
# Initialise a weight matrices
W1, W2 = init_weight_matrices()
# Optimiser and loss function
optimizer = torch.optim.Adam([W1, W2], lr=lr)
log_softmax_fn = nn.LogSoftmax(dim=1)
loss_fn = nn.NLLLoss()
"""Delay related update"""
optimizer_delay = delay_layer.optimizer_delay
print(f"Want loss for epoch 1 to be about {-np.log(1/num_classes):.2f}, multiply m by constant to get this")
loss_hist = []
for e in range(nb_epochs):
local_loss = []
for x_local, y_local in data_generator(discretise(ipds), spikes):
# Run network
"""Delay related update"""
# Apply the delays only to the input spikes
output = snn(x_local, W1, W2)
""""""
# Compute cross entropy loss
m = torch.mean(output, 1) # Mean across time dimension
loss = loss_fn(log_softmax_fn(m), y_local)
local_loss.append(loss.item())
# Update gradients
"""Delay related update"""
if trainable_delays:
optimizer.zero_grad()
optimizer_delay.zero_grad()
loss.backward()
optimizer_delay.step()
optimizer.step()
else:
optimizer.zero_grad()
loss.backward()
optimizer.step()
""""""
loss_hist.append(np.mean(local_loss))
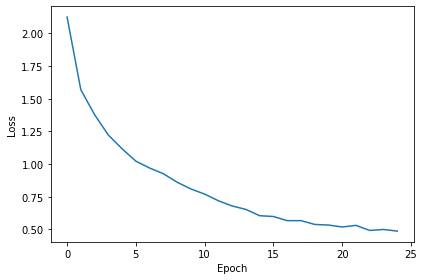
print("Epoch %i: loss=%.5f"%(e+1, np.mean(local_loss)))
# print(delay_layer.delays_out/ms)
# Plot the loss function over time
plt.plot(loss_hist)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.tight_layout()Want loss for epoch 1 to be about 2.48, multiply m by constant to get this
Epoch 1: loss=2.12471
Epoch 2: loss=1.56834
Epoch 3: loss=1.37786
Epoch 4: loss=1.22190
Epoch 5: loss=1.11655
Epoch 6: loss=1.02202
Epoch 7: loss=0.96948
Epoch 8: loss=0.92578
Epoch 9: loss=0.86076
Epoch 10: loss=0.80924
Epoch 11: loss=0.76976
Epoch 12: loss=0.71889
Epoch 13: loss=0.67908
Epoch 14: loss=0.65265
Epoch 15: loss=0.60454
Epoch 16: loss=0.59829
Epoch 17: loss=0.56674
Epoch 18: loss=0.56699
Epoch 19: loss=0.53785
Epoch 20: loss=0.53305
Epoch 21: loss=0.51829
Epoch 22: loss=0.53057
Epoch 23: loss=0.49170
Epoch 24: loss=0.49909
Epoch 25: loss=0.48674
#@title Visualise inputs and various delay effects
# Plot a few just to show how it looks
max_delay = delay_layer.max_delay
ipd, spikes = random_ipd_input_signal(8)
spikes_1 = spikes.cpu().clone()
spikes_2 = spikes.cpu().clone()
plt.figure(figsize=(10, 4), dpi=100)
for i in range(8):
plt.subplot(2, 4, i+1)
plt.imshow(spikes[i, :, :].T, aspect='auto', interpolation='nearest', cmap=plt.cm.gray_r)
plt.title(f'True IPD = {int(ipd[i]*180/np.pi)} deg', fontdict = {'fontsize' : 10})
if i>=4:
plt.xlabel('Time (steps)')
if i%4==0:
plt.ylabel('Input neuron index')
plt.suptitle('No delays', fontweight ="bold", x=0.0, y=1.0)
plt.tight_layout()
print('Delays before: ', delays_out_original/ms, '\n')
delays_out = delay_layer.delays_out.clone()
delays_out_print = torch.clip(delays_out.detach(), min=0, max=max_delay-ms)/ms
print('Delays after: ',delays_out_print)
delay_layer.delays_out = torch.nn.parameter.Parameter(delays_out_original, requires_grad=False)
spikes = delay_layer(spikes_1).detach().numpy()
plt.figure(figsize=(10, 4), dpi=100)
for i in range(8):
plt.subplot(2, 4, i+1)
plt.imshow(spikes[i, :, :].T, aspect='auto', interpolation='nearest', cmap=plt.cm.gray_r)
plt.title(f'True IPD = {int(ipd[i]*180/np.pi)} deg')
if i>=4:
plt.xlabel('Time (steps)')
if i%4==0:
plt.ylabel('Input neuron index')
plt.suptitle('Before training', fontweight ="bold", x=0.0, y=1.0)
plt.tight_layout()
delay_layer.delays_out = torch.nn.parameter.Parameter(delays_out, requires_grad=False)
spikes = delay_layer(spikes_2).detach().numpy()
plt.figure(figsize=(10, 4), dpi=100)
for i in range(8):
plt.subplot(2, 4, i+1)
plt.imshow(spikes[i, :, :].T, aspect='auto', interpolation='nearest', cmap=plt.cm.gray_r)
plt.title(f'True IPD = {int(ipd[i]*180/np.pi)} deg')
if i>=4:
plt.xlabel('Time (steps)')
if i%4==0:
plt.ylabel('Input neuron index')
plt.suptitle('After training', fontweight ="bold", x=0.0, y=1.0)
plt.tight_layout()Delays before: tensor([12.0, 34.0, 10.0, 46.0, 4.0, 40.0, 45.0, 7.0, 31.0, 35.0, 42.0, 48.0,
5.0, 1.0, 5.0, 47.0, 7.0, 41.0, 32.0, 25.0, 40.0, 2.0, 16.0, 1.0,
7.0, 49.0, 37.0, 45.0, 16.0, 17.0, 15.0, 26.0, 12.0, 49.0, 19.0, 18.0,
12.0, 37.0, 1.0, 11.0, 40.0, 38.0, 47.0, 46.0, 7.0, 9.0, 21.0, 16.0,
46.0, 20.0, 6.0, 3.0, 37.0, 40.0, 26.0, 41.0, 13.0, 15.0, 21.0, 14.0,
46.0, 44.0, 9.0, 14.0, 24.0, 2.0, 35.0, 3.0, 31.0, 23.0, 31.0, 26.0,
9.0, 25.0, 21.0, 40.0, 3.0, 40.0, 18.0, 6.0, 5.0, 1.0, 2.0, 28.0,
30.0, 22.0, 1.0, 26.0, 2.0, 17.0, 12.0, 4.0, 39.0, 40.0, 4.0, 1.0,
44.0, 16.0, 36.0, 27.0, 2.0, 17.0, 35.0, 24.0, 46.0, 20.0, 15.0, 19.0,
3.0, 7.0, 27.0, 9.0, 26.0, 38.0, 13.0, 29.0, 45.0, 33.0, 25.0, 23.0,
28.0, 8.0, 12.0, 47.0, 35.0, 47.0, 44.0, 49.0, 18.0, 26.0, 17.0, 39.0,
37.0, 37.0, 7.0, 3.0, 17.0, 41.0, 47.0, 36.0, 5.0, 4.0, 36.0, 10.0,
19.0, 13.0, 12.0, 14.0, 41.0, 16.0, 43.0, 2.0, 22.0, 9.0, 36.0, 8.0,
49.0, 32.0, 47.0, 49.0, 24.0, 14.0, 22.0, 28.0, 37.0, 28.0, 9.0, 47.0,
41.0, 34.0, 13.0, 1.0, 8.0, 36.0, 23.0, 1.0, 49.0, 12.0, 3.0, 14.0,
37.0, 30.0, 4.0, 6.0, 13.0, 11.0, 15.0, 35.0, 21.0, 44.0, 2.0, 46.0,
39.0, 34.0, 20.0, 36.0, 15.0, 42.0, 8.0, 13.0],
grad_fn=<DivBackward0>)
Delays after: tensor([49.0, 49.0, 49.0, 49.0, 0.0, 49.0, 49.0, 0.0, 49.0, 49.0, 49.0, 49.0,
0.0, 49.0, 41.1, 49.0, 41.4, 49.0, 49.0, 49.0, 49.0, 0.0, 49.0, 0.0,
43.4, 49.0, 49.0, 49.0, 49.0, 49.0, 48.8, 49.0, 49.0, 49.0, 49.0, 48.4,
46.2, 49.0, 0.0, 49.0, 49.0, 49.0, 49.0, 49.0, 49.0, 49.0, 49.0, 49.0,
49.0, 37.8, 44.6, 49.0, 49.0, 49.0, 44.0, 49.0, 49.0, 49.0, 49.0, 49.0,
49.0, 49.0, 0.0, 40.5, 49.0, 0.0, 49.0, 41.3, 49.0, 49.0, 49.0, 49.0,
41.4, 49.0, 49.0, 49.0, 0.0, 49.0, 49.0, 39.3, 42.1, 43.5, 0.0, 49.0,
49.0, 49.0, 0.0, 49.0, 0.0, 49.0, 49.0, 0.0, 49.0, 31.0, 0.0, 0.0,
49.0, 42.2, 49.0, 49.0, 49.0, 49.0, 49.0, 38.7, 49.0, 46.7, 42.5, 39.1,
30.9, 39.9, 49.0, 49.0, 49.0, 49.0, 44.2, 32.5, 49.0, 49.0, 49.0, 49.0,
39.7, 0.0, 39.9, 49.0, 49.0, 49.0, 49.0, 49.0, 41.6, 49.0, 40.0, 49.0,
49.0, 49.0, 49.0, 36.6, 46.3, 49.0, 49.0, 49.0, 49.0, 49.0, 49.0, 39.0,
49.0, 45.3, 49.0, 49.0, 49.0, 47.3, 49.0, 0.0, 49.0, 0.0, 49.0, 0.0,
49.0, 49.0, 49.0, 49.0, 49.0, 44.3, 35.8, 49.0, 44.3, 49.0, 49.0, 49.0,
49.0, 49.0, 45.4, 0.0, 49.0, 49.0, 49.0, 0.0, 49.0, 33.0, 49.0, 49.0,
49.0, 49.0, 0.0, 49.0, 44.9, 41.1, 43.1, 49.0, 49.0, 49.0, 49.0, 49.0,
49.0, 49.0, 45.9, 49.0, 39.1, 49.0, 48.0, 40.0])



Comment #4: This is a protoype of what I think might work and needs more work. Here is a list of things I think can be done regarding the work here:
Check the code works as intended
Code optimization to facilitate learning
Apply Method B: shift + clip
A dedicated optimizer or a robust and general way to update the gradients to ensure that the updated delays are whole numbers. The gradients are discrete and should be in multiples of dt.
Maybe a dedicated delays optimizer?
Other methods?
Finally, comments, suggestions and questions would be welcome and helpful. I am not an expert in this area so this might be slow. If anyone is any expert, I don’t mind handing over.