Edit2: I have collected most of the delay related functions and variables to a DelayLayer class. Applied surrogate update to delays as suggested by (Tomas Fiers, Markus Ghosh and Alessandro Galloni). In this update, method A is used. In addition, I completely changed the code of the delay layer forward function as there was a bug with the one supplied by pytorch (it was very time consuming to find and fix this bug). In this update, I will demonstrate that the delay layer works, apply to a modified sound the localization problem (I will explain why the modification) and state what are the challenges with 1-layer differentiable delays. Also, in this update, I will show conceptually how delays can be learned in a more biological SNN using Brian2.
I will start with the concept as shown in the below figure.
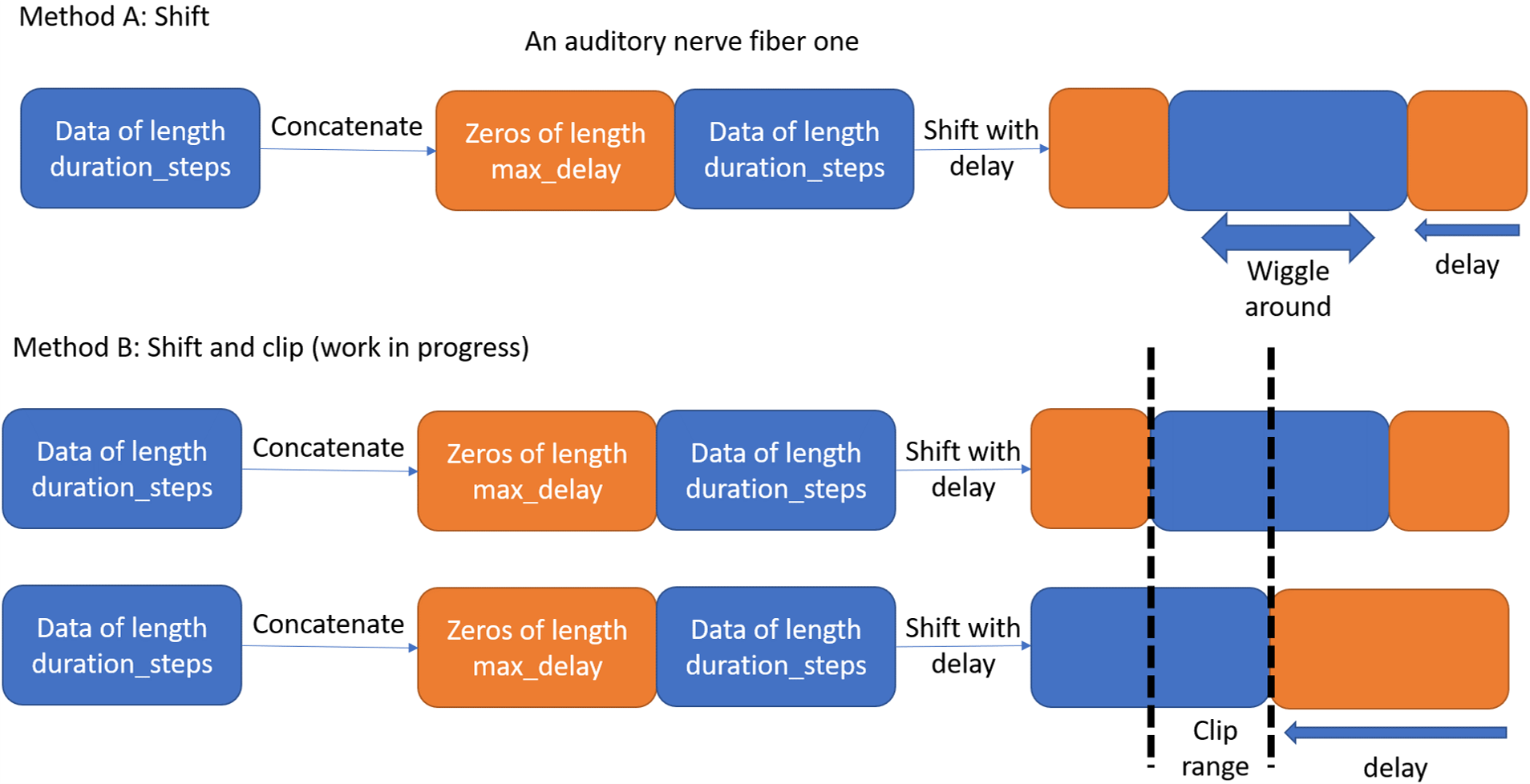
Method A: the aim is to pad the output spikes with a tensor of zeros then apply a delay. This will shift the spikes as shown in the figure, then the data will be surronded by zeros from both sides.
Delay toy problems¶
#@title Imports
!pip install brian2
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
import brian2 as br
dtype = torch.float
torch.set_printoptions(precision=8, sci_mode=False, linewidth=200)
np.set_printoptions(precision=10, suppress=True)
np.random.seed(0)
torch.manual_seed(0)#@title Defintions
# Stimulus and simulation parameters
DURATION_TRUE = 20 # Input pattern duration
MAX_DELAY = 40 # Maximum allowed delay
DURATION_ZEROS = 20 # Size of the zero padding to the input pattern
DURATION_STEPS = DURATION_ZEROS * 3 + DURATION_TRUE # Full duration length (used in synaptic integration)
EFFECTIVE_DURATION = DURATION_STEPS
NUMBER_CLASSES = 20
NUMBER_INPUTS = 3 # The larger the harder the problem
BATCH_SIZE = 500
NB_EPOCHS = 4000
TAU, TAU_DECAY, TAU_DECAY_FLAG = 10, 0.04, False # Decaying tau can lead to better performance put needs adjustment.
ROUND_DECIMALS = 4 # For the stability of differentiating delays
MAX_SUM = np.zeros((NUMBER_CLASSES,)) # A part of the loss function
MULTIPLY_ALL = False # Set to False for faster convergence or if there is no convergence.
FIX_FIRST_INPUT = True # Set to true for faster convergence or if there is no convergence.
PROP_ONES = 0.3 # Probability of spikes in a pattern
INPUT_PATTERN = np.random.choice([0, 1], size=(NUMBER_INPUTS, NUMBER_CLASSES, DURATION_TRUE),
p=[1-PROP_ONES, PROP_ONES])
INPUT_PATTERN_LENGTH = INPUT_PATTERN.shape[2]
INPUT_PATTERN_2 = np.random.choice([0, 1], size=(NUMBER_CLASSES, NUMBER_INPUTS, NUMBER_CLASSES, DURATION_TRUE),
p=[1-PROP_ONES, PROP_ONES])
INPUT_PATTERN_3 = np.zeros([NUMBER_INPUTS, NUMBER_CLASSES, DURATION_TRUE])
INPUT_PATTERN_3[:, :, :] = INPUT_PATTERN[0, 0, :]
SAME_PATTERN = True # Patterns of different classes are the same
if SAME_PATTERN:
INPUT_PATTERN = INPUT_PATTERN_3.copy()
ALL_RANDOM_FLAG = False # If true, the same neuron will output different spikes for different target neurons (Unsolvable for now)
SHOW_IMAGE = False # In results, show image or only significant input/output pairsCreates all the input-targets pairs for training. This function is called once.
#@title Generation of input-target pairs for training
def create_input_targets(duration=20, number_inputs=2, classes=20, duration_zeros=20):
inputs_temp = np.zeros([number_inputs, classes, duration])
zero_padding = np.zeros([number_inputs, classes, duration_zeros])
targets_temp = np.zeros(classes)
inputs_targets = []
if ALL_RANDOM_FLAG:
for idx in range(classes):
inputs_copy = INPUT_PATTERN_2[idx, :, :, :].copy()
inputs_copy = np.concatenate((zero_padding, zero_padding, inputs_copy, zero_padding), axis=2)
targets_copy = targets_temp.copy()
targets_copy[idx] = 1
inputs_targets.append((inputs_copy, targets_copy))
else:
for idx in range(classes):
inputs_temp[0, :, :] = INPUT_PATTERN[0, idx, :]
inputs_copy = inputs_temp.copy()
inputs_copy = np.concatenate((zero_padding, zero_padding, inputs_copy, zero_padding), axis=2)
for idy in np.arange(1, NUMBER_INPUTS, 1):
rand_poistion = np.random.randint(0, duration)
inputs_copy[idy, :, 2*duration_zeros + rand_poistion:2*duration_zeros + rand_poistion +
INPUT_PATTERN_LENGTH] = INPUT_PATTERN[idy, idx, :]
targets_copy = targets_temp.copy()
targets_copy[idx] = 1
inputs_targets.append((inputs_copy, targets_copy))
return inputs_targets#@title Getting the training patch
input_targets_all = create_input_targets(duration=DURATION_TRUE, number_inputs=NUMBER_INPUTS,
classes=NUMBER_CLASSES, duration_zeros=DURATION_ZEROS)
def generate_input_targets(in_tar, n=NUMBER_CLASSES):
while True:
yield in_tar[np.random.choice(n)]
def get_batch():
inputs, targets = [], []
for _ in range(BATCH_SIZE):
value = next(generate_input_targets(input_targets_all))
inputs.append(value[0])
targets.append(value[1])
yield torch.Tensor(np.array(inputs)), torch.Tensor(np.array(targets))#@title Delay layer
np.random.seed(0)
torch.manual_seed(0)
class DelayLayer(nn.Module):
""" Custom Delay Layer """
def __init__(self, max_delay_in=19, train_delays=True, num_ear=2,
constant_delays=False, constant_value=0, lr_delay=1e-3):
super().__init__()
self.max_delay = max_delay_in
self.trainable_delays = train_delays
self.number_inputs = NUMBER_INPUTS
self.constant_delays = constant_delays
self.constant_value = constant_value
self.lr_delay = lr_delay # Not fine tuned much, but improves performance on no_delays case
# self.effective_duration = duration_steps - max_delay_in
self.effective_duration = EFFECTIVE_DURATION
self.delays_out = self._init_delay_vector()
self.optimizer_delay = self._init_optimizer()
# Delays with constant or random initialisation
# Might think of other ways to initialize delays and their effect on performance
def _init_delay_vector(self):
if FIX_FIRST_INPUT:
self.number_inputs = NUMBER_INPUTS - 1
else:
self.number_inputs = NUMBER_INPUTS
if self.constant_delays:
delays = torch.nn.parameter.Parameter(torch.FloatTensor(
self.constant_value * np.ones((self.number_inputs, NUMBER_CLASSES), dtype=int)), requires_grad=True)
else:
delays_numpy = np.random.randint(1, self.max_delay,
size=(self.number_inputs, NUMBER_CLASSES), dtype=int)
delays = torch.nn.parameter.Parameter(torch.FloatTensor(delays_numpy), requires_grad=True)
return delays
def _init_optimizer(self):
optimizer_delay = torch.optim.SGD([self.delays_out], lr=self.lr_delay)
return optimizer_delay
def forward(self, spikes_in):
input_train = spikes_in[:, :, :, :, None]
if FIX_FIRST_INPUT:
input_first = input_train[:, 0:1, :, :, :]
input_train = input_train[:, 1:, :, :, :]
dlys = delay_fn(self.delays_out)
batch_size, inputs, classes, duration, _ = input_train.size()
# initialize M to identity transform and resize
translate_mat = np.array([[1., 0., 0.], [0., 1., 0.]])
translate_mat = torch.FloatTensor(np.resize(translate_mat, (batch_size, inputs, classes, 2, 3)))
# translate with delays
translate_mat[:, :, :, 0, 2] = 2 / (duration - 1) * dlys
# create normalized 1D grid and resize
x_t = np.linspace(-1, 1, duration)
y_t = np.zeros((1, duration)) # 1D: all y points are zeros
ones = np.ones(np.prod(x_t.shape))
grid = np.vstack([x_t.flatten(), y_t.flatten(), ones]) # an array of points (x, y, 1) shape (3, :)
grid = torch.FloatTensor(np.resize(grid, (batch_size, inputs, classes, 3, duration)))
# transform the sampling grid i.e. batch multiply
translate_grid = torch.matmul(translate_mat, grid)
# reshape to (num_batch, height, width, 2)
translate_grid = torch.transpose(translate_grid, 3, 4)
x_points = translate_grid[:, :, :, :, 0]
corr_center = ((x_points + 1.) * (duration - 1)) * 0.5
# grab 4 nearest corner points for each (x_t, y_t)
corr_left = torch.floor(torch.round(corr_center, decimals=ROUND_DECIMALS)).type(torch.int64)
corr_right = corr_left + 1
# Calculate weights
weight_right = (corr_right - corr_center)
weight_left = (corr_center - corr_left)
# Padding for values that are evaluated outside the input range
pad_right = torch.amax(corr_right) + 1 - duration
pad_left = torch.abs(torch.amin(corr_left))
zeros_right = torch.zeros(size=(batch_size, inputs, classes, pad_right, 1))
zeros_left = torch.zeros(size=(batch_size, inputs, classes, pad_left, 1))
input_train = torch.cat((input_train, zeros_right), dim=3)
# Get the new values after the transformation
value_left = input_train[np.arange(batch_size)[:, None, None, None], np.arange(inputs)[None, :, None, None],
np.arange(classes)[None, None, :, None], corr_left][:, :, :, :, 0]
value_right = input_train[np.arange(batch_size)[:, None, None, None], np.arange(inputs)[None, :, None, None],
np.arange(classes)[None, None, :, None], corr_right][:, :, :, :, 0]
# compute output
output_train = weight_right*value_left + weight_left*value_right
if FIX_FIRST_INPUT:
output_train = torch.concatenate((input_first[:, :, :, :, 0], output_train), dim=1)
return output_train#@title Surrogate Delays
np.random.seed(0)
torch.manual_seed(0)
class DelayUpdate(torch.autograd.Function):
@staticmethod
def forward(ctx, delays):
delays_forward = torch.round(torch.clamp(delays, min=-delay_layer.max_delay, max=delay_layer.max_delay))
return delays_forward
@staticmethod
def backward(ctx, grad_output):
delays_in = grad_output
return delays_in#@title Synaptic integration function
def snn(input_spikes, normal=True):
input_spikes = delay_layer(input_spikes) # Get the shifted input spikes after the delay applicaion
duration_in = delay_layer.effective_duration # Get the whole input duration for integration
v = torch.zeros((BATCH_SIZE, NUMBER_INPUTS, NUMBER_CLASSES, DURATION_STEPS), dtype=dtype)
v_out = torch.empty((BATCH_SIZE, 1, NUMBER_CLASSES, DURATION_STEPS), dtype=dtype)
if normal: # No visualization functions
alpha = np.exp(-1 / TAU)
for t in range(duration_in - 1):
v[:, :, :, t] = alpha * v[:, :, :, t-1] + input_spikes[:, :, :, t] # Apply decay to the input spikes
if MULTIPLY_ALL: # Multiply all spikes together
for idx in range(NUMBER_INPUTS-1):
v_mul = torch.mul(v[:, idx+1:, :, :], v[:, idx:idx+1, :, :]) # Multiply the input spikes
v_out = torch.concatenate((v_out, v_mul), dim=1)
v_out = torch.sum(v_out, dim=1) # Sum along the input dimension
v_out = torch.sum(v_out, dim=2) # Sum along the time dimension
else: # Pairwise multiplication with the first input spike
first_mat = v[:, 1:, :, :]
v_mul = torch.mul(first_mat, v[:, 0:1, :, :])
v_out = v_mul
v_out = torch.sum(v_out, dim=1)
v_out = torch.sum(v_out, dim=2)
else: # Visulization of the effect of TAU
sum_result = []
sum_result_total = []
choice_class, choice_batch = 4, 20
x = np.arange(int(v.size()[3]))
tau_range = np.linspace(0.01, 4, 12)
for tau_choice in tau_range:
alpha = np.exp(-1 / tau_choice)
for t in range(duration_in - 1):
v[:, :, :, t] = alpha * v[:, :, :, t-1] + input_spikes[:, :, :, t]
for roll_idx in range(duration_in):
if MULTIPLY_ALL:
for idx in range(NUMBER_INPUTS-1):
v_mul = torch.mul(v[:, idx+1:, :, :], v[:, idx:idx+1, :, :])
v_out = torch.concatenate((v_out, v_mul), dim=1)
v_out = torch.sum(v_out, dim=1)
v_out = torch.sum(v_out, dim=2)
else:
first_mat = v[:, 1:, :, :]
first_mat = np.roll(first_mat.detach().numpy(), roll_idx, axis=3)
first_mat = torch.FloatTensor(first_mat)
v_mul = torch.mul(first_mat, v[:, 0:1, :, :])
v_out = v_mul
v_out = torch.sum(v_out, dim=1)
v_out = torch.sum(v_out, dim=2)
sum_result.append(v_out[choice_batch, choice_class].detach().numpy())
sum_result_total.append(sum_result)
sum_result = []
sum_result_total = np.array(sum_result_total)
fig, axs = plt.subplots(3, 4, figsize=(20, 8), dpi=100)
for i, ax in enumerate(axs.flat):
ax.plot(x, sum_result_total[i, :])
ax.set_title(f'Tau = {np.round(tau_range[i], decimals=2)} ms')
if i >= 8:
ax.set(xlabel='Delay/time shift value (ms)')
if i % 4 == 0:
ax.set(ylabel='Sum value (au)')
fig.suptitle('Effect of TAU', fontweight="bold", x=0.5, y=1.0)
plt.tight_layout()
plt.show()
return v_out#@title Pre-training definitions
delay_layer = DelayLayer(lr_delay=0.2, constant_delays=False, constant_value=19)
delay_fn = DelayUpdate.apply
optimizer_delay_apply = delay_layer.optimizer_delay
log_softmax_fn = nn.LogSoftmax(dim=1)
softmax_fn = nn.Softmax(dim=1)
loss_fn = nn.NLLLoss()
loss_hist = []#@title Training routine
def training_loop(minimum_loss = 0.000001):
for e in range(NB_EPOCHS):
local_loss = []
for x_local, y_local in get_batch():
# Apply the delays only to the input spikes
output = snn(x_local)
# Get the corresponding targets from the batch
target = []
for i in range(BATCH_SIZE):
target.append(np.where(y_local[i] > 0.5))
target = torch.FloatTensor(np.array(target)).squeeze().to(torch.int64)
# A chessy loss function to calculate the maximum per output and set the maximum as the target.
# The idea is to learn the delays the maximizes the output of the multiplicative synapses.
max_sum = torch.amax(output, dim=1).detach()
# max_sum = 1.01*max_sum
for j in range(BATCH_SIZE):
index = target[j].item()
if TAU_DECAY_FLAG:
MAX_SUM[index] = max_sum[j]
else:
if MAX_SUM[index] < max_sum[j]:
MAX_SUM[index] = max_sum[j]
loss = 0
for j in range(BATCH_SIZE):
index = target[j].item()
loss_single = (output[j, index] - MAX_SUM[index]) ** 2 / BATCH_SIZE
loss += loss_single
# out_prop = log_softmax_fn(output)
# loss = loss_fn(out_prop, target)
local_loss.append(loss.item())
optimizer_delay_apply.zero_grad()
loss.backward()
optimizer_delay_apply.step()
""""""
if TAU_DECAY_FLAG:
TAU *= np.exp(-TAU_DECAY)
loss_hist.append(np.mean(local_loss))
print("Epoch %i: loss=%.5f"%(e+1, np.mean(local_loss)))
# print('Applied delays clamped: ', torch.round(torch.clamp(delay_layer.delays_out.flatten(),
# min=-delay_layer.max_delay, max=delay_layer.max_delay)), '\n\n\n\n\n')
# Visualization of the effect of delays on the input patterns
if np.mean(local_loss) < minimum_loss:
trial_input_all = []
for i in range(NUMBER_CLASSES):
trial_input_all.append(input_targets_all[i][0])
trial_input_all = np.array(trial_input_all)
trial_input = torch.FloatTensor(trial_input_all.copy())
trial_out = delay_layer.forward(trial_input).detach()
fig_1, axs_1 = plt.subplots(4, 5, figsize=(20, 8), dpi=100)
for i, ax in enumerate(axs_1.flat):
if SHOW_IMAGE:
ax.imshow(np.concatenate((trial_input[i, 0, :, :], trial_input[i, 1, :, :])), aspect='auto',
interpolation='nearest', cmap=plt.cm.gray_r)
else:
ax.imshow(trial_input[i, :, i, :], aspect='auto', interpolation='nearest', cmap=plt.cm.gray_r)
ax.set_title(f'Class {i}')
if i >= 15:
ax.set(xlabel='Time (steps)')
if i % 5 == 0:
ax.set(ylabel='Input neuron index')
fig_1.suptitle('Before training', fontweight="bold", x=0.5, y=1.0)
plt.tight_layout()
plt.show()
print('\n\n\n\n\n\n\n')
fig_2, axs_2 = plt.subplots(4, 5, figsize=(20, 8), dpi=100)
for i, ax in enumerate(axs_2.flat):
if SHOW_IMAGE:
ax.imshow(np.concatenate((trial_out[i, 0, :, :], trial_out[i, 1, :, :])), aspect='auto',
interpolation='nearest', cmap=plt.cm.gray_r)
else:
ax.imshow(trial_out[i, :, i, :], aspect='auto', interpolation='nearest', cmap=plt.cm.gray_r)
ax.set_title(f'Class {i}')
if i >= 15:
ax.set(xlabel='Time (steps)')
if i % 5 == 0:
ax.set(ylabel='Input neuron index')
fig_2.suptitle('After training', fontweight="bold", x=0.5, y=1.0)
plt.tight_layout()
plt.show()
break
training_loop()
Epoch 1: loss=4237.44092
Epoch 2: loss=358.86176
Epoch 3: loss=53.15290
Epoch 4: loss=22.14787
Epoch 5: loss=3.84989
Epoch 6: loss=3.40470
Epoch 7: loss=1.32817
Epoch 8: loss=0.89785
Epoch 9: loss=0.64848
Epoch 10: loss=2.31028
Epoch 11: loss=1.33180
Epoch 12: loss=0.02720
Epoch 13: loss=0.01695
Epoch 14: loss=0.01198
Epoch 15: loss=0.01562
Epoch 16: loss=0.01263
Epoch 17: loss=0.01366
Epoch 18: loss=0.78215
Epoch 19: loss=0.01041
Epoch 20: loss=0.01007
Epoch 21: loss=0.00940
Epoch 22: loss=0.00672
Epoch 23: loss=0.00840
Epoch 24: loss=0.01007
Epoch 25: loss=0.01108
Epoch 26: loss=0.00806
Epoch 27: loss=0.00907
Epoch 28: loss=0.00806
Epoch 29: loss=0.00705
Epoch 30: loss=0.47167
Epoch 31: loss=0.67675
Epoch 32: loss=0.55370
Epoch 33: loss=0.31243
Epoch 34: loss=0.62486
Epoch 35: loss=0.83315
Epoch 36: loss=0.52072
Epoch 37: loss=0.67693
Epoch 38: loss=0.00000


#@title Another example with different input patterns
SAME_PATTERN = False
NUMBER_INPUTS = 2
TAU = 30
INPUT_PATTERN = np.random.choice([0, 1], size=(NUMBER_INPUTS, NUMBER_CLASSES, DURATION_TRUE),
p=[1-PROP_ONES, PROP_ONES])
MAX_SUM = np.zeros((NUMBER_CLASSES,))
input_targets_all = create_input_targets(duration=DURATION_TRUE, number_inputs=NUMBER_INPUTS,
classes=NUMBER_CLASSES, duration_zeros=DURATION_ZEROS)
delay_layer = DelayLayer(lr_delay=0.2, constant_delays=False, constant_value=19)
optimizer_delay_apply = delay_layer.optimizer_delay
loss_hist = []
training_loop(minimum_loss = 0.03)
Epoch 1: loss=4623.93945
Epoch 2: loss=56.18170
Epoch 3: loss=38.36674
Epoch 4: loss=26.82403
Epoch 5: loss=18.32592
Epoch 6: loss=15.34432
Epoch 7: loss=13.53976
Epoch 8: loss=9.37796
Epoch 9: loss=6.84598
Epoch 10: loss=5.25477
Epoch 11: loss=6.19171
Epoch 12: loss=5.20127
Epoch 13: loss=5.30573
Epoch 14: loss=5.39644
Epoch 15: loss=5.34032
Epoch 16: loss=4.27515
Epoch 17: loss=3.60774
Epoch 18: loss=3.83571
Epoch 19: loss=3.84651
Epoch 20: loss=3.61390
Epoch 21: loss=3.16746
Epoch 22: loss=3.70379
Epoch 23: loss=3.73798
Epoch 24: loss=3.06282
Epoch 25: loss=3.05730
Epoch 26: loss=3.27841
Epoch 27: loss=3.03782
Epoch 28: loss=2.96965
Epoch 29: loss=1.51395
Epoch 30: loss=1.37212
Epoch 31: loss=1.30885
Epoch 32: loss=0.95687
Epoch 33: loss=1.00516
Epoch 34: loss=0.89970
Epoch 35: loss=0.80429
Epoch 36: loss=0.91749
Epoch 37: loss=0.85631
Epoch 38: loss=0.93246
Epoch 39: loss=1.04576
Epoch 40: loss=0.94055
Epoch 41: loss=0.86712
Epoch 42: loss=0.95459
Epoch 43: loss=1.09050
Epoch 44: loss=0.92072
Epoch 45: loss=0.93286
Epoch 46: loss=0.97262
Epoch 47: loss=1.06690
Epoch 48: loss=1.07849
Epoch 49: loss=0.89293
Epoch 50: loss=0.77315
Epoch 51: loss=0.89683
Epoch 52: loss=1.04678
Epoch 53: loss=0.94602
Epoch 54: loss=0.83521
Epoch 55: loss=0.78818
Epoch 56: loss=0.80720
Epoch 57: loss=0.91275
Epoch 58: loss=0.82485
Epoch 59: loss=0.79933
Epoch 60: loss=0.73283
Epoch 61: loss=0.72580
Epoch 62: loss=0.81974
Epoch 63: loss=0.54853
Epoch 64: loss=0.65712
Epoch 65: loss=0.58240
Epoch 66: loss=0.72489
Epoch 67: loss=0.74680
Epoch 68: loss=1.04107
Epoch 69: loss=0.66389
Epoch 70: loss=0.65396
Epoch 71: loss=0.70537
Epoch 72: loss=0.53787
Epoch 73: loss=0.66314
Epoch 74: loss=0.57297
Epoch 75: loss=0.59933
Epoch 76: loss=0.75146
Epoch 77: loss=0.67303
Epoch 78: loss=0.36173
Epoch 79: loss=0.73228
Epoch 80: loss=0.67364
Epoch 81: loss=0.66075
Epoch 82: loss=0.62546
Epoch 83: loss=0.62888
Epoch 84: loss=0.55497
Epoch 85: loss=0.72866
Epoch 86: loss=0.55379
Epoch 87: loss=0.56685
Epoch 88: loss=0.48566
Epoch 89: loss=0.43811
Epoch 90: loss=0.66049
Epoch 91: loss=0.46958
Epoch 92: loss=0.46007
Epoch 93: loss=0.36529
Epoch 94: loss=0.58252
Epoch 95: loss=0.54920
Epoch 96: loss=0.59013
Epoch 97: loss=0.59210
Epoch 98: loss=0.60501
Epoch 99: loss=0.67836
Epoch 100: loss=0.49547
Epoch 101: loss=0.44008
Epoch 102: loss=0.54384
Epoch 103: loss=0.48668
Epoch 104: loss=0.33313
Epoch 105: loss=0.51781
Epoch 106: loss=0.69796
Epoch 107: loss=0.66531
Epoch 108: loss=0.61805
Epoch 109: loss=0.63802
Epoch 110: loss=0.53037
Epoch 111: loss=0.65276
Epoch 112: loss=0.58364
Epoch 113: loss=0.52449
Epoch 114: loss=0.48695
Epoch 115: loss=0.46783
Epoch 116: loss=0.49511
Epoch 117: loss=0.50252
Epoch 118: loss=0.61636
Epoch 119: loss=0.38096
Epoch 120: loss=0.44517
Epoch 121: loss=0.65586
Epoch 122: loss=0.60240
Epoch 123: loss=0.46600
Epoch 124: loss=0.39327
Epoch 125: loss=0.53926
Epoch 126: loss=0.61154
Epoch 127: loss=0.46774
Epoch 128: loss=0.50334
Epoch 129: loss=0.66027
Epoch 130: loss=0.57547
Epoch 131: loss=0.53692
Epoch 132: loss=0.39373
Epoch 133: loss=0.50583
Epoch 134: loss=0.65346
Epoch 135: loss=0.65328
Epoch 136: loss=0.44292
Epoch 137: loss=0.60050
Epoch 138: loss=0.61278
Epoch 139: loss=0.60001
Epoch 140: loss=0.64018
Epoch 141: loss=0.51840
Epoch 142: loss=0.34510
Epoch 143: loss=0.32863
Epoch 144: loss=0.44133
Epoch 145: loss=0.46238
Epoch 146: loss=0.53872
Epoch 147: loss=0.63701
Epoch 148: loss=0.42453
Epoch 149: loss=0.56153
Epoch 150: loss=0.51857
Epoch 151: loss=0.44168
Epoch 152: loss=0.73708
Epoch 153: loss=0.51784
Epoch 154: loss=0.34757
Epoch 155: loss=0.67986
Epoch 156: loss=0.52166
Epoch 157: loss=0.34512
Epoch 158: loss=0.61894
Epoch 159: loss=0.49985
Epoch 160: loss=0.63623
Epoch 161: loss=0.51214
Epoch 162: loss=0.47560
Epoch 163: loss=0.58282
Epoch 164: loss=0.56520
Epoch 165: loss=0.58673
Epoch 166: loss=0.43518
Epoch 167: loss=0.31993
Epoch 168: loss=0.45449
Epoch 169: loss=0.67090
Epoch 170: loss=0.49137
Epoch 171: loss=0.58947
Epoch 172: loss=0.64656
Epoch 173: loss=0.51398
Epoch 174: loss=0.51146
Epoch 175: loss=0.51240
Epoch 176: loss=0.49206
Epoch 177: loss=0.51154
Epoch 178: loss=0.57560
Epoch 179: loss=0.45152
Epoch 180: loss=0.55364
Epoch 181: loss=0.51796
Epoch 182: loss=0.66743
Epoch 183: loss=0.64833
Epoch 184: loss=0.61142
Epoch 185: loss=0.82251
Epoch 186: loss=0.04043
Epoch 187: loss=0.04091
Epoch 188: loss=0.03080
Epoch 189: loss=0.03568
Epoch 190: loss=0.03590
Epoch 191: loss=0.03627
Epoch 192: loss=0.03914
Epoch 193: loss=0.03698
Epoch 194: loss=0.03452
Epoch 195: loss=0.03967
Epoch 196: loss=0.03435
Epoch 197: loss=0.03901
Epoch 198: loss=0.03406
Epoch 199: loss=0.03353
Epoch 200: loss=0.03848
Epoch 201: loss=0.03513
Epoch 202: loss=0.03290
Epoch 203: loss=0.03706
Epoch 204: loss=0.03826
Epoch 205: loss=0.03872
Epoch 206: loss=0.03405
Epoch 207: loss=0.03473
Epoch 208: loss=0.03550
Epoch 209: loss=0.03622
Epoch 210: loss=0.03300
Epoch 211: loss=0.03342
Epoch 212: loss=0.03568
Epoch 213: loss=0.03550
Epoch 214: loss=0.04022
Epoch 215: loss=0.03525
Epoch 216: loss=0.03639
Epoch 217: loss=0.03190
Epoch 218: loss=0.04299
Epoch 219: loss=0.03516
Epoch 220: loss=0.03371
Epoch 221: loss=0.03146
Epoch 222: loss=0.03489
Epoch 223: loss=0.03730
Epoch 224: loss=0.03585
Epoch 225: loss=0.03996
Epoch 226: loss=0.03660
Epoch 227: loss=0.03801
Epoch 228: loss=0.03492
Epoch 229: loss=0.02853


The most important parameters for training are the TAU, TAU_DECAY and the learning rate. The TAU_DECAY effect is not yet optimized and needs further investigations. The synaptic integration function is based on multiplicative interaction (non-linear) at the distal dendrites and then summation at the soma.
#@title Effect of TAU
out = next(get_batch())
_ = snn(out[0], normal=False)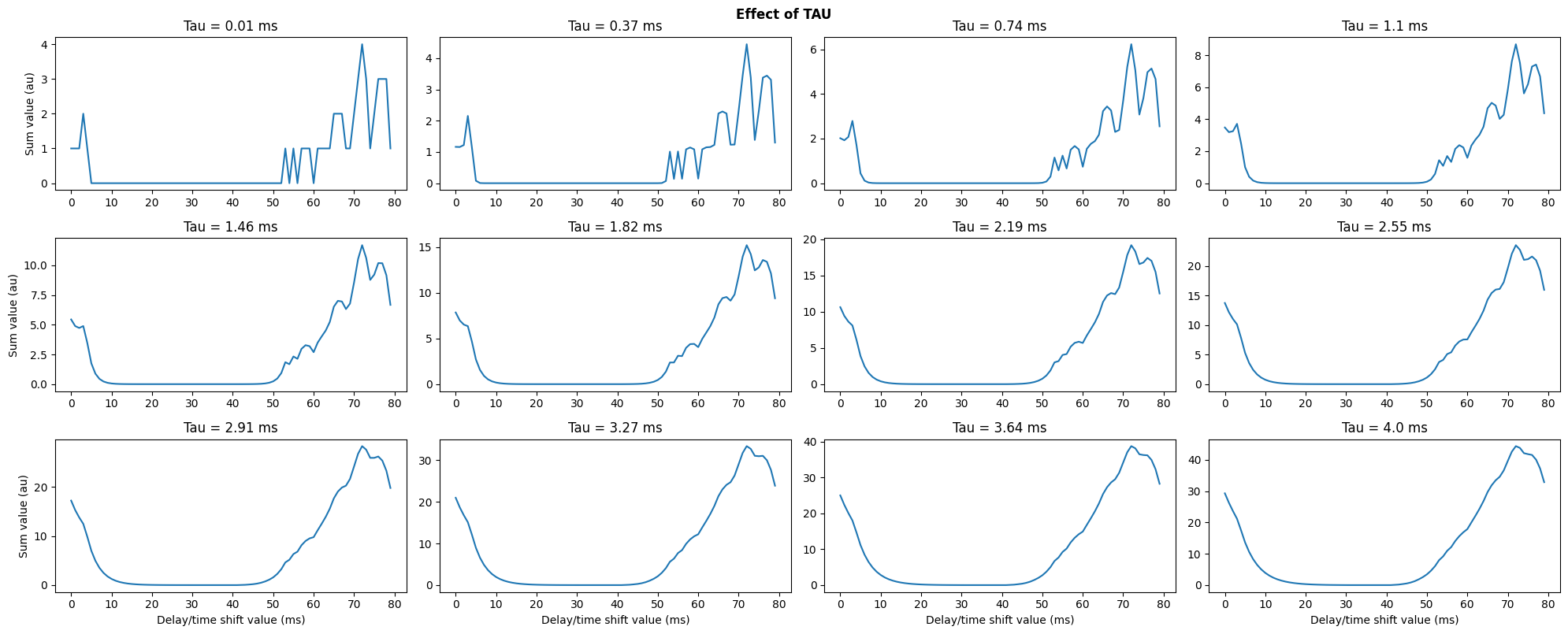
As been seen from the above examples, the delay learning problem is a non convex optimization, when 1) we try to learn dealys in one layer, and 2) use the above loss and synaptic integration function. Non-convex optimization is tricky and there is a whole field in ML for non-convex optimization. Increasing TAU for the above cases leads to a smoother function, but also leads to a misallignement of the spikes. TAU_DECAY should help zoom in on a better spike alignment.
Simplified sound localization problem with one delay layer¶
Here, we will try to learn ipds with a single delay layer. However, in contrast to the original example, the input patterns are fixed during training. Stochastic input leads to stochastic output. The best loss function for stochastic output is the cross entropy loss. Sadly, it is difficult to learn delays with this loss function. I don’t know exactly why, but I believe it has to do with the fact that the output of the softmax has all delay layers parameters into consideration. Thus, while one tries to optimize a specific delay for a spike train, one also un-optimize the other delays.
#@title Relevant definitions
torch.set_printoptions(precision=8, sci_mode=False, linewidth=200)
np.set_printoptions(precision=10, suppress=True)
np.random.seed(0)
torch.manual_seed(0)
# Not using Brian so we just use these constants to make equations look nicer below
SECOND = 1
MS = 1e-3
HZ = 1
# Stimulus and simulation parameters
DT = 1 * MS # large time step to make simulations run faster for tutorial
ANF_PER_EAR = 100 # repeats of each ear with independent noise # number of classes
ENVELOPE_POWER = 10 # higher values make sharper envelopes, easier
RATE_MAX = 600 * HZ # maximum Poisson firing rate
F = 50 * HZ # stimulus frequency
DURATION = 50 * MS # stimulus duration
DURATION_STEPS = int(np.round(DURATION / DT))
ANG_STEP = 5
NUMBER_CLASSES = int(180/ANG_STEP)
# Training parameters
NB_EPOCHS = 2000 # quick, it won't have converged
BATCH_SIZE = 200
N_TRAINING_BATCHES = 64
N_TESTING_BATCHES = 32
device = device = torch.device("cpu")
"""Delay paramters and functions"""
MAX_DELAY = 20 # Assumed to be in ms
MAX_DELAY_DURATION = MAX_DELAY
NUM_EAR = 2
NUMBER_INPUTS = NUM_EAR
LR_DELAY = 0.05
EFFECTIVE_DURATION = MAX_DELAY * 3 + int(np.round(DURATION / DT))
TAU, TAU_DECAY, TAU_DECAY_FLAG = 40, 0.01, True
ROUND_DECIMALS = 4
MAX_SUM = np.zeros((BATCH_SIZE,))
FIX_FIRST_INPUT = True
SHOW_IMAGE = False
ALL_RANDOM = 1#@title Input target generators
torch.set_printoptions(precision=8, sci_mode=False, linewidth=200)
np.set_printoptions(precision=10, suppress=True)
np.random.seed(0)
torch.manual_seed(0)
def input_signal():
ipds_ang = np.arange(-90, 90, ANG_STEP)
ipds_hot = np.zeros((NUMBER_CLASSES, NUMBER_CLASSES))
for idx in range(NUMBER_CLASSES):
ipds_hot[idx, idx] = 1
ipds_rad = ipds_ang*np.pi/180
num_classes = len(ipds_ang)
time_axis = np.arange(DURATION_STEPS) * DT # array of times
phi = 2*np.pi*(F * time_axis + np.random.rand()) # array of phases corresponding to those times with random offset
phi = 2 * np.pi * (F * time_axis) # array of phases corresponding to those times with random offset
theta = np.zeros((num_classes, NUM_EAR, num_classes, DURATION_STEPS))
zeros_pad = np.zeros((num_classes, NUM_EAR, num_classes, MAX_DELAY_DURATION))
theta[:, 0, :, :] = phi[np.newaxis, np.newaxis, :]
theta[:, 1, :, :] = phi[np.newaxis, np.newaxis, :] + ipds_rad[:, np.newaxis, np.newaxis]
# now generate Poisson spikes at the given firing rate as in the previous notebook
spikes_out = np.random.rand(num_classes, NUM_EAR, num_classes, DURATION_STEPS) < RATE_MAX * \
DT * (0.5 * (1 + np.sin(theta))) ** ENVELOPE_POWER
spikes_out = np.concatenate((zeros_pad, spikes_out, zeros_pad, zeros_pad), axis=3)
return spikes_out, ipds_hot
def input_signal_2():
ipds_ang = np.arange(-90, 90, ANG_STEP)
ipds_hot = np.zeros((NUMBER_CLASSES, NUMBER_CLASSES))
for idx in range(NUMBER_CLASSES):
ipds_hot[idx, idx] = 1
ipds_rad = ipds_ang*np.pi/180
num_classes = len(ipds_ang)
time_axis = np.arange(DURATION_STEPS) * DT # array of times
phi = 2*np.pi*(F * time_axis + np.random.rand()) # array of phases corresponding to those times with random offset
phi = 2 * np.pi * (F * time_axis + np.random.rand())
theta = np.zeros((num_classes, NUM_EAR, DURATION_STEPS))
zeros_pad = np.zeros((num_classes, NUM_EAR, MAX_DELAY_DURATION))
theta[:, 0, :] = phi[np.newaxis, np.newaxis, :]
theta[:, 1, :] = phi[np.newaxis, np.newaxis, :] + ipds_rad[np.newaxis, :, np.newaxis]
# now generate Poisson spikes at the given firing rate as in the previous notebook
spikes_out = np.random.rand(num_classes, NUM_EAR, DURATION_STEPS) < RATE_MAX * \
DT * (0.5 * (1 + np.sin(theta))) ** ENVELOPE_POWER
spikes_out = np.concatenate((zeros_pad, spikes_out, zeros_pad, zeros_pad), axis=2)
spikes_temp = np.zeros((num_classes, NUM_EAR, num_classes, EFFECTIVE_DURATION))
spikes_one = spikes_out[:, 0, :]
spikes_two = spikes_out[:, 1, :]
spikes_temp[:, 0, :, :] = spikes_one
spikes_temp[:, 1, :, :] = spikes_two
spikes_out = spikes_temp.copy()
spikes_out = np.swapaxes(spikes_out, 0, 2)
return spikes_out, ipds_hot
def input_signal_3(ipd_choice=0):
ipds_hot = np.zeros((NUMBER_CLASSES,))
ipds_hot[ipd_choice] = 1
ipds_rad = ipd_choice*np.pi/180
time_axis = np.arange(DURATION_STEPS) * DT # array of times
phi = 2*np.pi*(F * time_axis + np.random.rand()) # array of phases corresponding to those times with random offset
theta = np.zeros((NUM_EAR, DURATION_STEPS))
zeros_pad = np.zeros((NUM_EAR, MAX_DELAY_DURATION))
theta[0, :] = phi[np.newaxis, :]
theta[1, :] = phi[np.newaxis, :] + ipds_rad
# now generate Poisson spikes at the given firing rate as in the previous notebook
spikes_temp = np.random.rand(NUM_EAR, DURATION_STEPS) < RATE_MAX * \
DT * (0.5 * (1 + np.sin(theta))) ** ENVELOPE_POWER
spikes_temp = np.concatenate((zeros_pad, spikes_temp, zeros_pad, zeros_pad), axis=1)
spikes_out = np.zeros((NUM_EAR, NUMBER_CLASSES, EFFECTIVE_DURATION))
spikes_out[:, :, :] = spikes_temp[:, np.newaxis, :]
return spikes_out, ipds_hot#@title Batch generator function and related
torch.set_printoptions(precision=8, sci_mode=False, linewidth=200)
np.set_printoptions(precision=10, suppress=True)
np.random.seed(0)
torch.manual_seed(0)
if ALL_RANDOM == 0:
spikes_out_all, ipds_hot_all = input_signal()
elif ALL_RANDOM == 1:
spikes_out_all, ipds_hot_all = input_signal_2()
else:
spikes_out_all, ipds_hot_all = input_signal_3()
def generate_input_targets(spikes_in=0, ipds_in=0, n=NUMBER_CLASSES):
while True:
choice = np.random.choice(n)
if ALL_RANDOM == 0 or ALL_RANDOM == 1:
yield spikes_in[choice], ipds_in[choice]
else:
yield input_signal_3(ipd_choice=choice)
fig, axs = plt.subplots(6, 6, figsize=(20, 8), dpi=100)
ipds_range = np.arange(-90, 90, ANG_STEP)
for i, ax in enumerate(axs.flat):
if SHOW_IMAGE:
ax.imshow(np.concatenate((spikes_out_all[i, 0, :, :], spikes_out_all[i, 1, :, :])), aspect='auto',
interpolation='nearest', cmap=plt.cm.gray_r)
else:
ax.imshow(spikes_out_all[i, :, i, :], aspect='auto', interpolation='nearest', cmap=plt.cm.gray_r)
ax.set_title(f'IPD = {ipds_range[i]}')
if i >= 30:
ax.set(xlabel='Time (steps)')
if i % 6 == 0:
ax.set(ylabel='Input neuron index')
fig.suptitle('Classes', fontweight="bold", x=0.5, y=1.0)
plt.tight_layout()
plt.show()
def get_batch():
inputs, targets = [], []
for _ in range(BATCH_SIZE):
if ALL_RANDOM == 0 or ALL_RANDOM == 1:
value = next(generate_input_targets(spikes_in=spikes_out_all, ipds_in=ipds_hot_all))
inputs.append(value[0])
targets.append(value[1])
else:
value_input, value_target = next(generate_input_targets())
inputs.append(value_input)
targets.append(value_target)
yield torch.Tensor(np.array(inputs)), torch.Tensor(np.array(targets))
#@title Synaptic integration for the sound localization problem
np.random.seed(0)
torch.manual_seed(0)
def snn_sl(input_spikes):
input_spikes = delay_layer(input_spikes)
duration_in = delay_layer.effective_duration
""""""
v = torch.zeros((BATCH_SIZE, NUMBER_INPUTS, NUMBER_CLASSES, delay_layer.effective_duration), dtype=dtype)
input_spikes_add = torch.sum(input_spikes, dim=1)
alpha = np.exp(-1 / TAU)
for t in range(duration_in - 1):
v[:, :, :, t] = alpha * v[:, :, :, t-1] + input_spikes[:, :, :, t]
first_mat = v[:, 1:, :, :]
v_mul = torch.mul(first_mat, v[:, 0:1, :, :])
v_out = v_mul
v_out = torch.sum(v_out, dim=1)
v_out = torch.sum(v_out, dim=2)
return v_out#@title Training loop and parameters
np.random.seed(0)
torch.manual_seed(0)
delay_layer = DelayLayer(lr_delay=0.5, constant_delays=False, constant_value=0, max_delay_in=MAX_DELAY)
delay_fn = DelayUpdate.apply
optimizer_delay_apply = delay_layer.optimizer_delay
loss_hist = []
max_sum_holder = np.zeros((NUMBER_CLASSES,))
for e in range(NB_EPOCHS):
local_loss = []
for x_local, y_local in get_batch():
# Run network
"""Delay related update"""
# Apply the delays only to the input spikes
output = snn_sl(x_local)
# print('Max: ', torch.amax(output_snn))
max_sum = torch.amax(output, dim=1).detach()
# max_sum = 1.01*max_sum
target = []
for i in range(BATCH_SIZE):
target.append(np.where(y_local[i] > 0.5))
target = torch.FloatTensor(np.array(target)).squeeze().to(torch.int64)
sum_counter = np.zeros((NUMBER_CLASSES,))
for j in range(BATCH_SIZE):
index = target[j].item()
if ALL_RANDOM == 0 or ALL_RANDOM == 1:
if TAU_DECAY_FLAG:
MAX_SUM[index] = max_sum[j]
else:
if MAX_SUM[index] < max_sum[j]:
MAX_SUM[index] = max_sum[j]
else:
sum_counter[index] += 1
MAX_SUM[index] += max_sum[j]
if ALL_RANDOM == 2:
for k in range(NUMBER_CLASSES):
MAX_SUM[k] /= sum_counter[k]
max_sum_holder[k] += MAX_SUM[k]
""""""
loss = 0
for j in range(BATCH_SIZE):
index = target[j].item()
if ALL_RANDOM == 0 or ALL_RANDOM == 1:
loss_single = (output[j, index] - MAX_SUM[index]) ** 2 / BATCH_SIZE
else:
loss_single = (output[j, index] - max_sum_holder[index]/(e+1)) ** 2 / BATCH_SIZE
loss += loss_single
local_loss.append(loss.item())
optimizer_delay_apply.zero_grad()
loss.backward()
optimizer_delay_apply.step()
""""""
if TAU_DECAY_FLAG:
if TAU >= 2:
TAU *= np.exp(-TAU_DECAY)
else:
TAU = 2
# print('Tau:', TAU)
loss_hist.append(np.mean(local_loss))
print("Epoch %i: loss=%.5f"%(e+1, np.mean(local_loss)))
print('Tau: ', TAU)
# print('Actual delays clamped: ', torch.round(torch.clamp(delay_layer.delays_out.flatten(),
# min=-delay_layer.max_delay, max=delay_layer.max_delay)), '\n\n\n\n\n')
# if e >= 10:
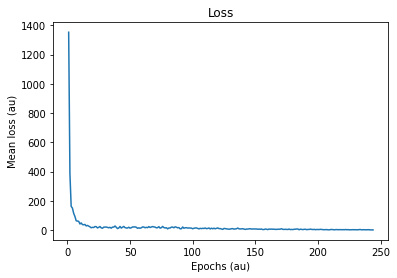
if np.mean(local_loss) < 1:
plt.plot(np.arange(1, e+2, 1), loss_hist)
plt.title('Loss')
plt.xlabel('Epochs (au)')
plt.ylabel('Mean loss (au)')
plt.show()
print('\n\n\n\n\n')
trial_input_all = spikes_out_all.copy()
trial_input = torch.FloatTensor(trial_input_all.copy())
trial_out = delay_layer.forward(trial_input).detach()
fig_1, axs_1 = plt.subplots(6, 6, figsize=(20, 8), dpi=100)
for i, ax in enumerate(axs_1.flat):
if SHOW_IMAGE:
ax.imshow(np.concatenate((trial_input[i, 0, :, :], trial_input[i, 1, :, :])), aspect='auto',
interpolation='nearest', cmap=plt.cm.gray_r)
else:
ax.imshow(trial_input[i, :, i, :], aspect='auto', interpolation='nearest', cmap=plt.cm.gray_r)
ax.set_title(f'Class {i}')
if i >= 30:
ax.set(xlabel='Time (steps)')
if i % 6 == 0:
ax.set(ylabel='Input neuron index')
fig_1.suptitle('Before training', fontweight="bold", x=0.5, y=1.0)
plt.tight_layout()
fig_2, axs_2 = plt.subplots(6, 6, figsize=(20, 8), dpi=100)
for i, ax in enumerate(axs_2.flat):
if SHOW_IMAGE:
ax.imshow(np.concatenate((trial_out[i, 0, :, :], trial_out[i, 1, :, :])), aspect='auto',
interpolation='nearest', cmap=plt.cm.gray_r)
else:
ax.imshow(trial_out[i, :, i, :], aspect='auto', interpolation='nearest', cmap=plt.cm.gray_r)
ax.set_title(f'Class {i}')
if i >= 30:
ax.set(xlabel='Time (steps)')
if i % 6 == 0:
ax.set(ylabel='Input neuron index')
fig_2.suptitle('After training', fontweight="bold", x=0.5, y=1.0)
plt.tight_layout()
plt.show()
break
Epoch 1: loss=1353.12097
Tau: 39.601993349966726
Epoch 2: loss=385.64023
Tau: 39.20794693227022
Epoch 3: loss=162.11420
Tau: 38.81782134194034
Epoch 4: loss=150.11247
Tau: 38.43157756609294
Epoch 5: loss=114.06781
Tau: 38.04917698002858
Epoch 6: loss=92.72813
Tau: 37.67058134336997
Epoch 7: loss=63.33299
Tau: 37.29575279623795
Epoch 8: loss=61.49543
Tau: 36.92465385546545
Epoch 9: loss=59.54112
Tau: 36.55724741084915
Epoch 10: loss=41.32266
Tau: 36.19349672143841
Epoch 11: loss=48.68990
Tau: 35.83336541186116
Epoch 12: loss=37.05945
Tau: 35.476817468686335
Epoch 13: loss=35.99608
Tau: 35.12381723682249
Epoch 14: loss=38.08598
Tau: 34.77432941595227
Epoch 15: loss=28.23213
Tau: 34.428319057002355
Epoch 16: loss=31.54223
Tau: 34.0857515586485
Epoch 17: loss=26.88283
Tau: 33.74659266385539
Epoch 18: loss=21.90092
Tau: 33.41080845645092
Epoch 19: loss=15.48784
Tau: 33.07836535773453
Epoch 20: loss=18.45501
Tau: 32.74923012311932
Epoch 21: loss=17.40580
Tau: 32.42336983880753
Epoch 22: loss=23.66299
Tau: 32.100751918499185
Epoch 23: loss=23.01353
Tau: 31.781344100133406
Epoch 24: loss=14.53311
Tau: 31.465114442662184
Epoch 25: loss=18.46913
Tau: 31.152031322856242
Epoch 26: loss=24.10169
Tau: 30.8420634321427
Epoch 27: loss=14.86154
Tau: 30.53517977347418
Epoch 28: loss=12.36142
Tau: 30.23134965822907
Epoch 29: loss=19.61755
Tau: 29.930542703142663
Epoch 30: loss=20.01555
Tau: 29.63272882726877
Epoch 31: loss=20.64687
Tau: 29.337878248971627
Epoch 32: loss=18.27295
Tau: 29.045961482947696
Epoch 33: loss=15.52657
Tau: 28.756949337277106
Epoch 34: loss=18.50960
Tau: 28.47081291050445
Epoch 35: loss=12.94699
Tau: 28.187523588748597
Epoch 36: loss=19.95142
Tau: 27.9070530428413
Epoch 37: loss=20.08875
Tau: 27.629373225494245
Epoch 38: loss=27.54248
Tau: 27.354456368494294
Epoch 39: loss=18.35809
Tau: 27.08227497992665
Epoch 40: loss=10.06758
Tau: 26.81280184142563
Epoch 41: loss=14.03065
Tau: 26.546010005452835
Epoch 42: loss=24.69521
Tau: 26.281872792602332
Epoch 43: loss=13.40544
Tau: 26.020363788932723
Epoch 44: loss=19.06274
Tau: 25.761456843325718
Epoch 45: loss=24.61539
Tau: 25.505126064870996
Epoch 46: loss=16.50147
Tau: 25.251345820277106
Epoch 47: loss=14.13602
Tau: 25.0000907313081
Epoch 48: loss=13.82368
Tau: 24.751335672245702
Epoch 49: loss=19.20291
Tau: 24.50505576737671
Epoch 50: loss=12.89548
Tau: 24.261226388505406
Epoch 51: loss=15.70004
Tau: 24.01982315249071
Epoch 52: loss=21.09970
Tau: 23.780821918807845
Epoch 53: loss=20.77584
Tau: 23.54419878713428
Epoch 54: loss=21.52193
Tau: 23.30993009495966
Epoch 55: loss=18.92995
Tau: 23.077992415219544
Epoch 56: loss=11.71974
Tau: 22.848362553952672
Epoch 57: loss=15.12626
Tau: 22.621017547981563
Epoch 58: loss=12.38079
Tau: 22.39593466261616
Epoch 59: loss=15.07993
Tau: 22.17309138938036
Epoch 60: loss=21.48374
Tau: 21.952465443761138
Epoch 61: loss=20.21634
Tau: 21.734034762980073
Epoch 62: loss=15.86156
Tau: 21.517777503787062
Epoch 63: loss=18.49417
Tau: 21.30367204027597
Epoch 64: loss=16.19379
Tau: 21.091696961722025
Epoch 65: loss=23.38701
Tau: 20.881831070440725
Epoch 66: loss=17.56892
Tau: 20.674053379668052
Epoch 67: loss=20.89153
Tau: 20.46834311146178
Epoch 68: loss=23.83150
Tau: 20.264679694623666
Epoch 69: loss=21.19172
Tau: 20.063042762642304
Epoch 70: loss=20.23312
Tau: 19.863412151656465
Epoch 71: loss=15.03346
Tau: 19.665767898438688
Epoch 72: loss=16.35732
Tau: 19.47009023839895
Epoch 73: loss=23.04282
Tau: 19.27635960360818
Epoch 74: loss=13.08586
Tau: 19.08455662084146
Epoch 75: loss=15.90813
Tau: 18.894662109640674
Epoch 76: loss=24.68317
Tau: 18.706657080396454
Epoch 77: loss=16.99631
Tau: 18.52052273244921
Epoch 78: loss=14.21069
Tau: 18.336240452209026
Epoch 79: loss=15.86852
Tau: 18.15379181129432
Epoch 80: loss=8.06238
Tau: 17.97315856468895
Epoch 81: loss=14.08141
Tau: 17.794322648917735
Epoch 82: loss=13.89972
Tau: 17.61726618024006
Epoch 83: loss=19.85428
Tau: 17.441971452861512
Epoch 84: loss=20.16722
Tau: 17.268420937163278
Epoch 85: loss=15.56303
Tau: 17.096597277949158
Epoch 86: loss=21.85654
Tau: 16.926483292710042
Epoch 87: loss=19.45346
Tau: 16.75806196990565
Epoch 88: loss=15.14135
Tau: 16.591316467263347
Epoch 89: loss=17.05534
Tau: 16.42623011009391
Epoch 90: loss=8.36248
Tau: 16.262786389624058
Epoch 91: loss=8.78945
Tau: 16.100968961345533
Epoch 92: loss=20.98201
Tau: 15.940761643380661
Epoch 93: loss=12.30544
Tau: 15.782148414864139
Epoch 94: loss=15.37646
Tau: 15.625113414340937
Epoch 95: loss=16.09756
Tau: 15.469640938180142
Epoch 96: loss=13.49572
Tau: 15.315715439004574
Epoch 97: loss=14.20966
Tau: 15.163321524136046
Epoch 98: loss=13.58517
Tau: 15.012443954056074
Epoch 99: loss=13.17207
Tau: 14.863067640881921
Epoch 100: loss=8.66474
Tau: 14.715177646857786
Epoch 101: loss=12.08540
Tau: 14.568759182861026
Epoch 102: loss=13.94268
Tau: 14.423797606923225
Epoch 103: loss=14.14501
Tau: 14.280278422765988
Epoch 104: loss=11.47108
Tau: 14.1381872783513
Epoch 105: loss=7.81698
Tau: 13.997509964446309
Epoch 106: loss=11.68165
Tau: 13.858232413202392
Epoch 107: loss=9.82894
Tau: 13.72034069674836
Epoch 108: loss=11.74033
Tau: 13.58382102579766
Epoch 109: loss=10.70165
Tau: 13.448659748269426
Epoch 110: loss=13.79136
Tau: 13.314843347923274
Epoch 111: loss=9.64855
Tau: 13.182358443007654
Epoch 112: loss=10.62483
Tau: 13.05119178492167
Epoch 113: loss=14.06410
Tau: 12.921330256890208
Epoch 114: loss=7.63406
Tau: 12.792760872652247
Epoch 115: loss=12.54577
Tau: 12.66547077516222
Epoch 116: loss=8.68384
Tau: 12.539447235304303
Epoch 117: loss=12.62425
Tau: 12.414677650619492
Epoch 118: loss=8.54806
Tau: 12.291149544045341
Epoch 119: loss=11.57768
Tau: 12.168850562668254
Epoch 120: loss=14.35135
Tau: 12.047768476488177
Epoch 121: loss=9.77049
Tau: 11.927891177195587
Epoch 122: loss=9.89096
Tau: 11.80920667696066
Epoch 123: loss=7.48342
Tau: 11.691703107234467
Epoch 124: loss=4.45891
Tau: 11.575368717562116
Epoch 125: loss=10.85267
Tau: 11.460191874407693
Epoch 126: loss=9.95683
Tau: 11.346161059990903
Epoch 127: loss=7.95581
Tau: 11.23326487113528
Epoch 128: loss=7.05795
Tau: 11.121492018127855
Epoch 129: loss=5.69763
Tau: 11.010831323590182
Epoch 130: loss=6.73603
Tau: 10.901271721360592
Epoch 131: loss=9.12727
Tau: 10.792802255387562
Epoch 132: loss=9.69670
Tau: 10.685412078634101
Epoch 133: loss=6.19761
Tau: 10.579090451993045
Epoch 134: loss=7.49015
Tau: 10.473826743213126
Epoch 135: loss=8.78557
Tau: 10.369610425835745
Epoch 136: loss=13.67541
Tau: 10.26643107814232
Epoch 137: loss=8.27962
Tau: 10.164278382112096
Epoch 138: loss=7.33273
Tau: 10.063142122390344
Epoch 139: loss=8.19497
Tau: 9.96301218526681
Epoch 140: loss=8.91780
Tau: 9.863878557664343
Epoch 141: loss=6.36783
Tau: 9.765731326137567
Epoch 142: loss=4.34566
Tau: 9.668560675881542
Epoch 143: loss=6.52460
Tau: 9.572356889750266
Epoch 144: loss=6.60315
Tau: 9.477110347284954
Epoch 145: loss=8.30223
Tau: 9.38281152375199
Epoch 146: loss=8.77865
Tau: 9.289450989190437
Epoch 147: loss=6.59674
Tau: 9.197019407469037
Epoch 148: loss=7.35332
Tau: 9.105507535352594
Epoch 149: loss=7.24584
Tau: 9.014906221577633
Epoch 150: loss=6.78096
Tau: 8.925206405937276
Epoch 151: loss=7.13117
Tau: 8.83639911837521
Epoch 152: loss=5.57855
Tau: 8.748475478088672
Epoch 153: loss=6.41530
Tau: 8.661426692640363
Epoch 154: loss=5.32988
Tau: 8.575244057079198
Epoch 155: loss=6.85670
Tau: 8.489918953069802
Epoch 156: loss=3.19197
Tau: 8.405442848030669
Epoch 157: loss=3.73811
Tau: 8.321807294280898
Epoch 158: loss=6.73877
Tau: 8.239003928195418
Epoch 159: loss=5.60066
Tau: 8.157024469368617
Epoch 160: loss=2.98613
Tau: 8.075860719786295
Epoch 161: loss=6.83685
Tau: 7.995504563005858
Epoch 162: loss=5.63963
Tau: 7.915947963344665
Epoch 163: loss=6.41808
Tau: 7.837182965076452
Epoch 164: loss=5.64700
Tau: 7.759201691635754
Epoch 165: loss=5.95951
Tau: 7.681996344830242
Epoch 166: loss=4.31304
Tau: 7.605559204060898
Epoch 167: loss=4.71990
Tau: 7.529882625549948
Epoch 168: loss=5.38997
Tau: 7.454959041576475
Epoch 169: loss=5.48980
Tau: 7.3807809597196465
Epoch 170: loss=6.12953
Tau: 7.307340962109461
Epoch 171: loss=8.83580
Tau: 7.234631704684959
Epoch 172: loss=4.48581
Tau: 7.1626459164598035
Epoch 173: loss=4.34626
Tau: 7.0913763987951866
Epoch 174: loss=5.03573
Tau: 7.020816024679949
Epoch 175: loss=4.51292
Tau: 6.950957738017879
Epoch 176: loss=3.80305
Tau: 6.881794552922094
Epoch 177: loss=6.72920
Tau: 6.81331955301645
Epoch 178: loss=2.89473
Tau: 6.745525890743893
Epoch 179: loss=4.38400
Tau: 6.6784067866817
Epoch 180: loss=3.05528
Tau: 6.611955528863533
Epoch 181: loss=5.38629
Tau: 6.5461654721082345
Epoch 182: loss=5.80855
Tau: 6.4810300373553025
Epoch 183: loss=7.16014
Tau: 6.416542711006982
Epoch 184: loss=6.85755
Tau: 6.352697044276899
Epoch 185: loss=1.95744
Tau: 6.289486652545175
Epoch 186: loss=6.01446
Tau: 6.226905214719963
Epoch 187: loss=4.22013
Tau: 6.164946472605328
Epoch 188: loss=2.94799
Tau: 6.103604230275425
Epoch 189: loss=5.14187
Tau: 6.042872353454904
Epoch 190: loss=5.24984
Tau: 5.982744768905471
Epoch 191: loss=2.65007
Tau: 5.923215463818567
Epoch 192: loss=4.04453
Tau: 5.864278485214074
Epoch 193: loss=4.00943
Tau: 5.805927939345017
Epoch 194: loss=6.33573
Tau: 5.748157991108185
Epoch 195: loss=4.27981
Tau: 5.69096286346061
Epoch 196: loss=3.30567
Tau: 5.634336836841867
Epoch 197: loss=4.75652
Tau: 5.578274248602105
Epoch 198: loss=2.37875
Tau: 5.5227694924357795
Epoch 199: loss=3.79014
Tau: 5.467817017821021
Epoch 200: loss=3.23031
Tau: 5.413411329464574
Epoch 201: loss=3.39018
Tau: 5.359546986752265
Epoch 202: loss=4.65483
Tau: 5.306218603204934
Epoch 203: loss=4.06171
Tau: 5.253420845939789
Epoch 204: loss=2.69542
Tau: 5.201148435137102
Epoch 205: loss=2.27096
Tau: 5.1493961435122335
Epoch 206: loss=2.60991
Tau: 5.098158795792894
Epoch 207: loss=3.14145
Tau: 5.047431268201614
Epoch 208: loss=1.51326
Tau: 4.997208487943361
Epoch 209: loss=1.29615
Tau: 4.947485432698256
Epoch 210: loss=3.15713
Tau: 4.898257130119339
Epoch 211: loss=3.68911
Tau: 4.849518657335329
Epoch 212: loss=3.02957
Tau: 4.801265140458331
Epoch 213: loss=1.39443
Tau: 4.753491754096447
Epoch 214: loss=2.75070
Tau: 4.706193720871229
Epoch 215: loss=3.13267
Tau: 4.659366310939939
Epoch 216: loss=2.38005
Tau: 4.613004841522561
Epoch 217: loss=2.88683
Tau: 4.5671046764335195
Epoch 218: loss=2.73985
Tau: 4.521661225618054
Epoch 219: loss=2.24632
Tau: 4.476669944693214
Epoch 220: loss=2.69914
Tau: 4.432126334493414
Epoch 221: loss=2.02085
Tau: 4.388025940620514
Epoch 222: loss=3.44153
Tau: 4.344364352998377
Epoch 223: loss=2.09297
Tau: 4.301137205431855
Epoch 224: loss=2.89165
Tau: 4.2583401751701695
Epoch 225: loss=1.49925
Tau: 4.21596898247463
Epoch 226: loss=1.91793
Tau: 4.174019390190657
Epoch 227: loss=1.92974
Tau: 4.132487203324064
Epoch 228: loss=2.36612
Tau: 4.091368268621554
Epoch 229: loss=2.29312
Tau: 4.050658474155391
Epoch 230: loss=2.15236
Tau: 4.010353748912204
Epoch 231: loss=2.25177
Tau: 3.97045006238588
Epoch 232: loss=1.73012
Tau: 3.9309434241745147
Epoch 233: loss=3.16567
Tau: 3.891829883581364
Epoch 234: loss=3.17825
Tau: 3.8531055292197736
Epoch 235: loss=1.40809
Tau: 3.814766488622037
Epoch 236: loss=2.33726
Tau: 3.7768089278521457
Epoch 237: loss=2.03929
Tau: 3.7392290511223907
Epoch 238: loss=1.02334
Tau: 3.7020231004137827
Epoch 239: loss=1.64083
Tau: 3.6651873551002456
Epoch 240: loss=2.50362
Tau: 3.6287181315765515
Epoch 241: loss=1.80854
Tau: 3.5926117828899566
Epoch 242: loss=1.06747
Tau: 3.556864698375504
Epoch 243: loss=1.19760
Tau: 3.521473303294953
Epoch 244: loss=0.81534
Tau: 3.486434058479302


For 36 classes, one layer of differentiable delays and an un-optimized loss function: the performance isn’t that good, so I will not focus much on visualization of performance metrics.
#@title Test performance
trial_count = 50
test_array = []
np.random.seed(0)
torch.manual_seed(0)
x_train, y_train = next(get_batch())
output = snn_sl(x_train)
max_index = torch.argmax(output, dim=1).detach().numpy()
target = []
for i in range(BATCH_SIZE):
target.append(np.where(y_train[i] > 0.5))
target = torch.FloatTensor(np.array(target)).squeeze().to(torch.int64)
diff_pred = torch.abs(target-max_index)
plt.hist(diff_pred*ANG_STEP)
plt.title('Training bacth diff. between predictions in degree')
plt.xlabel('Difference (degree)')
plt.ylabel('Count (au)')
plt.show()
print('\n\n')
for _ in range(trial_count):
if ALL_RANDOM == 0:
spikes_out_all, ipds_hot_all = input_signal()
elif ALL_RANDOM == 1:
spikes_out_all, ipds_hot_all = input_signal_2()
else:
spikes_out_all, ipds_hot_all = input_signal_3()
x_test, y_test = next(get_batch())
output = snn_sl(x_test)
max_index = torch.argmax(output, dim=1).detach().numpy()
target = []
for i in range(BATCH_SIZE):
target.append(np.where(y_test[i] > 0.5))
target = torch.FloatTensor(np.array(target)).squeeze().to(torch.int64)
diff_pred = torch.abs(target-max_index)
test_array.extend(list(diff_pred.detach().numpy()))
diff_pred = np.array(test_array)
plt.hist(diff_pred*ANG_STEP)
plt.title('Testing bacth diff. between predictions in degree')
plt.xlabel('Difference (degree)')
plt.ylabel('Count (au)')
plt.show()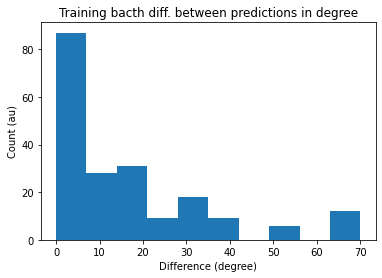
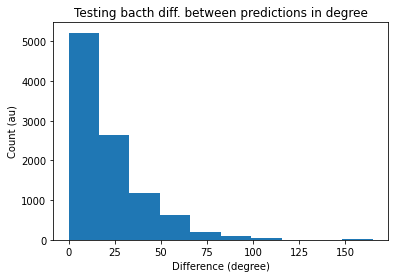
In the next example, I will add an output layer with trainable weights and train with cross-entropy for the harder case where the input is dynamic.
#@title Relevant definitions
BETA_SPIKE = 5
OUT_SIZE = NUMBER_CLASSES
THRESHOLD = 0.5
TAU, TAU_DECAY, TAU_DECAY_FLAG = 5, 0.01, False
LR_WEIGHTS = 0.001
LR_DELAY = 20
ALL_RANDOM = 2#@title Weight initialization
np.random.seed(0)
torch.manual_seed(0)
# Weights and uniform weight initialisation
def init_weight_matrix():
W = nn.Parameter(torch.empty((NUMBER_CLASSES, OUT_SIZE), device=device, dtype=dtype, requires_grad=True))
fan_in, _ = nn.init._calculate_fan_in_and_fan_out(W)
bound = 1 / np.sqrt(fan_in)
nn.init.uniform_(W, -bound, bound)
return W#@title Surrogate spike
np.random.seed(0)
torch.manual_seed(0)
class SurrGradSpike(torch.autograd.Function):
@staticmethod
def forward(ctx, input):
ctx.save_for_backward(input)
out = torch.zeros_like(input)
out[input > 0] = 1.0
return out
@staticmethod
def backward(ctx, grad_output):
input, = ctx.saved_tensors
# Original SPyTorch/SuperSpike gradient
# This seems to be a typo or error? But it works well
#grad = grad_output/(100*torch.abs(input)+1.0)**2
# Sigmoid
grad = grad_output*BETA_SPIKE*torch.sigmoid(BETA_SPIKE*input)*(1-torch.sigmoid(BETA_SPIKE*input))
return grad#@title New synaptic integration function
np.random.seed(0)
torch.manual_seed(0)
batch_choice = 5
def snn_sl1(input_spikes):
input_spikes = delay_layer(input_spikes)
duration_in = delay_layer.effective_duration
""""""
v = torch.zeros((BATCH_SIZE, NUMBER_INPUTS, NUMBER_CLASSES, delay_layer.effective_duration), dtype=dtype)
vm = torch.zeros((BATCH_SIZE, NUMBER_CLASSES, delay_layer.effective_duration), dtype=dtype)
s = torch.zeros((BATCH_SIZE, NUMBER_CLASSES, delay_layer.effective_duration), dtype=dtype)
v_rec = torch.zeros((BATCH_SIZE, NUMBER_CLASSES, delay_layer.effective_duration), dtype=dtype)
input_spikes_add = torch.sum(input_spikes, dim=1)
alpha = np.exp(-1 / TAU)
for t in range(duration_in - 1):
v[:, :, :, t] = (alpha * v[:, :, :, t-1] + input_spikes[:, :, :, t]) * (1-s[:, None, :, t-1])
first_mat = v[:, 1:, :, t].clone()
second_mat = v[:, 0:1, :, t].clone()
vm[:, :, t] = torch.mul(first_mat, second_mat).squeeze()
s[:, :, t] = spike_fn(vm[:, :, t]-THRESHOLD)
h = torch.einsum("abc,bd->adc", (s, WEIGHTS))
for t in range(duration_in - 1):
v_rec[:, :, t] = alpha * v_rec[:, :, t-1] + h[:, :, t]
# v = v.detach().numpy()
# v_image = np.concatenate((v[batch_choice, 0, :, :], v[batch_choice, 1, :, :]))
# plt.imshow(v_image)
# plt.colorbar()
# plt.show()
# vm = vm.detach().numpy()
# plt.imshow(vm[batch_choice])
# plt.colorbar()
# plt.show()
# plt.imshow(s[batch_choice].detach().numpy())
# plt.show()
return v_rec#@title Training loop
torch.autograd.set_detect_anomaly(True)
np.random.seed(0)
torch.manual_seed(0)
spike_fn = SurrGradSpike.apply
WEIGHTS = init_weight_matrix()
delay_layer = DelayLayer(lr_delay=LR_DELAY, constant_delays=False, constant_value=0, max_delay_in=MAX_DELAY)
optimizer_delay_apply = delay_layer.optimizer_delay
delay_fn = DelayUpdate.apply
optimizer_weights = torch.optim.Adam([WEIGHTS], lr=LR_WEIGHTS)
log_softmax_fn = nn.LogSoftmax(dim=1)
loss_fn = nn.NLLLoss()
loss_hist = []
for e in range(NB_EPOCHS):
local_loss = []
for x_local, y_local in get_batch():
output = snn_sl1(x_local)
output = torch.sum(output, dim=2)
target = []
for i in range(BATCH_SIZE):
target.append(np.where(y_local[i] > 0.5))
target = torch.FloatTensor(np.array(target)).squeeze().to(torch.int64)
loss = loss_fn(log_softmax_fn(output), target)
local_loss.append(loss.item())
optimizer_delay_apply.zero_grad()
optimizer_weights.zero_grad()
loss.backward()
optimizer_delay_apply.step()
optimizer_weights.step()
""""""
loss_hist.append(np.mean(local_loss))
print("Epoch %i: loss=%.5f"%(e+1, np.mean(local_loss)))
# print('Actual delays clamped: ', torch.round(torch.clamp(delay_layer.delays_out.flatten(),
# min=-delay_layer.max_delay, max=delay_layer.max_delay)), '\n\n\n\n\n')
# if e >= 1:
if (np.mean(local_loss) < 0.001) or (e > 50):
break
trial_input_all = spikes_out_all.copy()
trial_input = torch.FloatTensor(trial_input_all.copy())
trial_out = delay_layer.forward(trial_input).detach()
fig_1, axs_1 = plt.subplots(3, 4, figsize=(20, 8), dpi=100)
for i, ax in enumerate(axs_1.flat):
if SHOW_IMAGE:
ax.imshow(np.concatenate((trial_input[i, 0, :, :], trial_input[i, 1, :, :])), aspect='auto',
interpolation='nearest', cmap=plt.cm.gray_r)
else:
ax.imshow(trial_input[i, :, i, :], aspect='auto', interpolation='nearest', cmap=plt.cm.gray_r)
ax.set_title(f'Class {i}')
if i >= 36:
ax.set(xlabel='Time (steps)')
if i % 9 == 0:
ax.set(ylabel='Input neuron index')
fig_1.suptitle('Before training', fontweight="bold", x=0.5, y=1.0)
plt.tight_layout()
fig_2, axs_2 = plt.subplots(3, 4, figsize=(20, 8), dpi=100)
for i, ax in enumerate(axs_2.flat):
if SHOW_IMAGE:
ax.imshow(np.concatenate((trial_out[i, 0, :, :], trial_out[i, 1, :, :])), aspect='auto',
interpolation='nearest', cmap=plt.cm.gray_r)
else:
ax.imshow(trial_out[i, :, i, :], aspect='auto', interpolation='nearest', cmap=plt.cm.gray_r)
ax.set_title(f'Class {i}')
if i >= 36:
ax.set(xlabel='Time (steps)')
if i % 9 == 0:
ax.set(ylabel='Input neuron index')
fig_2.suptitle('After training', fontweight="bold", x=0.5, y=1.0)
plt.tight_layout()
plt.show()
Epoch 1: loss=11.04266
Epoch 2: loss=9.53374
Epoch 3: loss=8.18771
Epoch 4: loss=8.53678
Epoch 5: loss=8.01341
Epoch 6: loss=7.82801
Epoch 7: loss=7.01900
Epoch 8: loss=5.98131
Epoch 9: loss=6.41223
Epoch 10: loss=6.03342
Epoch 11: loss=5.91816
Epoch 12: loss=5.73771
Epoch 13: loss=5.40665
Epoch 14: loss=5.90104
Epoch 15: loss=5.55983
Epoch 16: loss=5.55448
Epoch 17: loss=5.41602
Epoch 18: loss=5.02097
Epoch 19: loss=5.37294
Epoch 20: loss=5.28181
Epoch 21: loss=5.10512
Epoch 22: loss=4.73427
Epoch 23: loss=5.11504
Epoch 24: loss=5.02654
Epoch 25: loss=5.05402
Epoch 26: loss=4.87612
Epoch 27: loss=4.92842
Epoch 28: loss=4.91075
Epoch 29: loss=4.91004
Epoch 30: loss=4.60573
Epoch 31: loss=4.72401
Epoch 32: loss=4.45368
Epoch 33: loss=4.54074
Epoch 34: loss=4.62440
Epoch 35: loss=4.43938
Epoch 36: loss=4.39366
Epoch 37: loss=4.47433
Epoch 38: loss=4.50037
Epoch 39: loss=4.56359
Epoch 40: loss=4.44698
Epoch 41: loss=4.42153
Epoch 42: loss=4.36636
Epoch 43: loss=4.49143
Epoch 44: loss=4.39918
Epoch 45: loss=4.42150
Epoch 46: loss=4.41810
Epoch 47: loss=4.38056
Epoch 48: loss=4.16940
Epoch 49: loss=4.36035
Epoch 50: loss=4.34757
Epoch 51: loss=4.36279
Epoch 52: loss=4.40486
Co-training of delays and weights still needs some work. I havn’t had enough time, but I will try to focus on it from now on.
Concept + little Brian implementation of a biologically plausible learning mechanism of delays¶
It should be noted outright that, as far as I know, delays can’t be changed dynamically during runtime in Brian2. Regardless, I will show a concept with some code of how to learn delays. Also, delays can be introduced in brian via a multistage lagging variable. This idea is take from the book Spikes, Decisions and Actions by Wilson.
It should be noted that delays for pattern matching or output maximization can be inferred from the maximum of the temporal convolution of two spike trains. However, knowing the maximum of a temporal convolution entitles knowing the future in a running spike train. In the following conceptual study, I will demonstrate how this can be bypassed.
Biologically plausible concept for learning delays
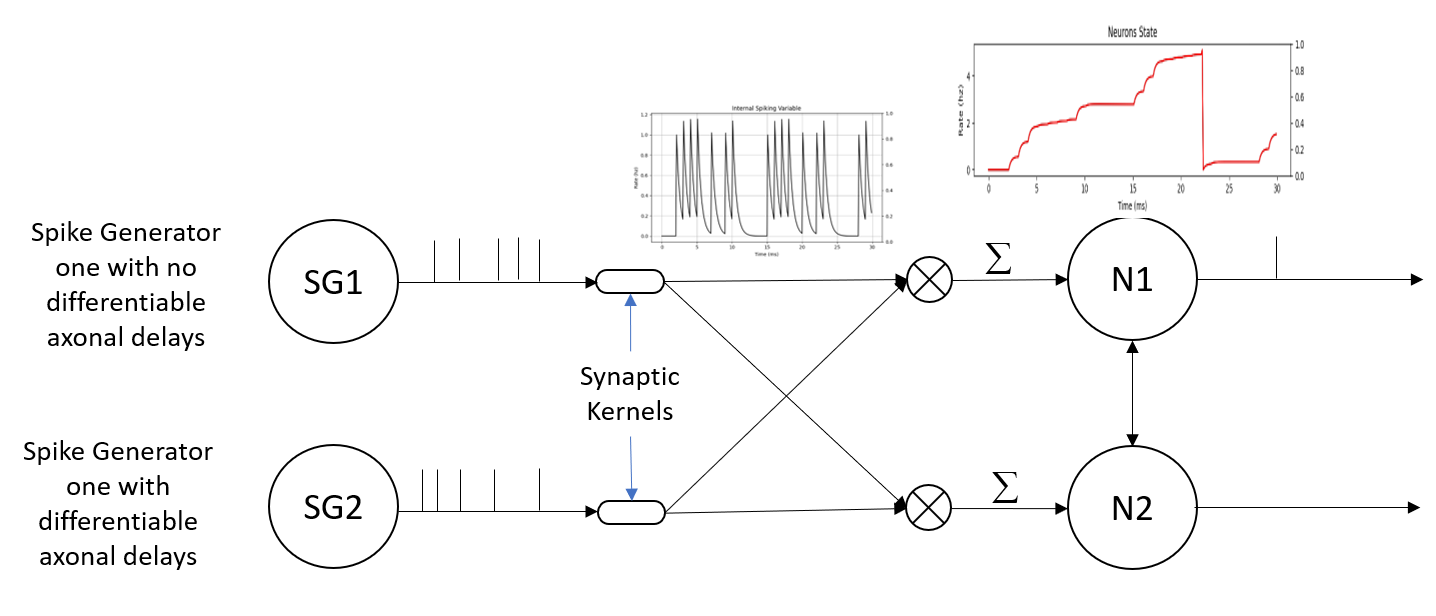
Here we have two spike generators SG1 and SG2. SG2 can have its axonal delays learned, while SG1 can’t! The spike trains from both generators go through an exponentially decaying synaptic kernel as shown. Then, the outputs of the kernels are multiplied and summed at the soma as shown on the right figure. This happens for both neurons N1 and N2. The difference between N1 and N2 is the initial delay value from SG2 to them. Since, the delay is different for both neurons, one neuron while have a higher integrated input then the other. The neuron with the higher internal state will fire first and inhibit the other. While the other neuron is inhibited, it will signal SG2 to change the respective synaptic delay.
#@title Neuronal class and parameters
np.random.seed(0)
br.devices.device.seed(0)
class DelayLearning:
def __init__(self):
self.para = {'tau': 1000, 'delay_fixed': 1, 'th': 8, 'tau_th': 50, 'tau_ds1': 0, 'tau_ds2': 1}
self.model_one = '''
dv_1/dt = 1/(tau*ms) * (-v_1 + 2000*s_1*s_2) : 1
ds_1/dt = -s_1/(0.5*ms) : 1
ds_2/dt = -s_2/(0.5*ms) : 1
dv_th1/dt = -v_th1/(tau_th*ms) : 1
d_1 : second
'''
self.model_two = '''
dv_2/dt = (1/(tau*ms)) * (-v_2 + 2000*s_1*s_2): 1
ds_1/dt = -s_1/(0.5*ms) : 1
ds_2/dt = -s_2/(0.5*ms) : 1
dv_th2/dt = -v_th2/(tau_th*ms) : 1
d_2 : second
'''#@title Relevant definitions
SEED = True
if SEED:
np.random.seed(0)
br.devices.device.seed(0)
SIMULATION_DURATION = 30 * br.ms # Simulation time
NUM_NEURONS = (1, 1, 1, 1) # Number of neurons for different neuronal model in a neural circuit
NEURON_MODELS = DelayLearning()
br.prefs.codegen.target = 'numpy'
LIST_PARA = list(NEURON_MODELS.para.keys())
LIST_VALUE = list(NEURON_MODELS.para.values())
DEFAULT_PARA = NEURON_MODELS.para.copy()
PARA_DIS_MAX = 5
PARA_DIS_MAX = np.amin([PARA_DIS_MAX, len(NEURON_MODELS.para)])
NEURON_GROUPS = {0: NEURON_MODELS.model_one, 1: NEURON_MODELS.model_two}
TIME_PERIOD = 10
TIME_EXTENSION = 3
REPETITION_TIMES = 80
PROP_ONES = 0.5
INPUT_PATTERN = np.random.choice([0, 1], size=(TIME_PERIOD,), p=[1-PROP_ONES, PROP_ONES])
INPUT_PATTERN = np.where(INPUT_PATTERN > 0.9)[0] + 1
SPIKE_TIMES = []
for idy in range(REPETITION_TIMES):
SPIKE_TIMES.append(INPUT_PATTERN+(TIME_PERIOD+TIME_EXTENSION)*idy)
SPIKE_TIMES = np.array(SPIKE_TIMES).flatten() * br.ms#@title Simulation run
np.random.seed(0)
br.devices.device.seed(0)
for k, v in NEURON_MODELS.para.items():
exec("%s = %d" % (k, v))
delay_value = NEURON_MODELS.para['delay_fixed'] * br.ms
threshold_initial = NEURON_MODELS.para['th']
g_1 = br.SpikeGeneratorGroup(1, [0] * len(list(SPIKE_TIMES)), SPIKE_TIMES, dt=0.1 * br.ms)
g_2 = br.SpikeGeneratorGroup(1, [0] * len(list(SPIKE_TIMES)), SPIKE_TIMES, dt=0.1 * br.ms)
neuron_group_one = br.NeuronGroup(NUM_NEURONS[0], NEURON_GROUPS[0], dt=0.1 * br.ms, method='rk4',
threshold='v_1 >= v_th1', reset='v_1 = 0')
neuron_group_two = br.NeuronGroup(NUM_NEURONS[1], NEURON_GROUPS[1], dt=0.1 * br.ms, method='rk4',
threshold='v_2 >= v_th2', reset='v_2 = 0')
neuron_group_one.v_th1 = threshold_initial
neuron_group_two.v_th2 = threshold_initial
neuron_group_one.d_1 = 0*br.ms
neuron_group_two.d_2 = 1*br.ms
s_11 = br.Synapses(g_1, neuron_group_one, on_pre='s_1_post += 1', dt=0.1 * br.ms, delay=delay_value)
s_11.connect()
s_12 = br.Synapses(g_1, neuron_group_two, on_pre='s_1_post += 1', dt=0.1 * br.ms, delay=delay_value)
s_12.connect()
s_21 = br.Synapses(g_2, neuron_group_one, on_pre='''s_2_post += 1
delay = d_1''', on_post='''v_th1 = threshold_initial''', dt=0.1 * br.ms)
s_21.connect()
s_21.delay = 2*br.ms
s_22 = br.Synapses(g_2, neuron_group_two, on_pre='''s_2_post += 1
delay = d_2''', on_post='''v_th2 = threshold_initial''', dt=0.1 * br.ms)
s_22.connect()
s_22.delay = 4*br.ms
s_ab = br.Synapses(neuron_group_one, neuron_group_two, on_pre='''v_2_post = 0
d_2 += 1*ms
v_th2 = threshold_initial''', dt=0.1 * br.ms)
s_ab.connect()
s_ba = br.Synapses(neuron_group_two, neuron_group_one, on_pre='''v_1_post = 0
d_1 += 1*ms
v_th1 = threshold_initial''', dt=0.1 * br.ms)
s_ba.connect()
state_mon_1 = br.StateMonitor(neuron_group_one, 'v_1', record=True)
state_mon_2 = br.StateMonitor(neuron_group_two, 'v_2', record=True)
state_mon_3 = br.StateMonitor(neuron_group_one, 's_1', record=True)
state_mon_4 = br.StateMonitor(neuron_group_one, 's_2', record=True)
state_mon_7 = br.StateMonitor(neuron_group_two, 's_2', record=True)
state_mon_5 = br.StateMonitor(neuron_group_one, 'v_th1', record=True)
state_mon_6 = br.StateMonitor(neuron_group_two, 'v_th2', record=True)
spikemon_1 = br.SpikeMonitor(neuron_group_one)
spikemon_2 = br.SpikeMonitor(neuron_group_two)
br.run(SIMULATION_DURATION)#@title Visualization of variables
fig, axs = plt.subplots(3, 2, figsize=(10, 10), dpi=100)
axs[0, 0].plot(state_mon_1.t / br.ms, state_mon_1.v_1[0])
axs[0, 0].set_title('Neuron one state')
axs[0, 1].plot(state_mon_2.t / br.ms, state_mon_2.v_2[0])
axs[0, 1].set_title('Neuron two state')
axs[1, 0].plot(state_mon_3.t / br.ms, state_mon_3.s_1[0])
axs[1, 0].set_title('S1 of Neuron one')
axs[1, 1].plot(state_mon_4.t / br.ms, state_mon_4.s_2[0])
axs[1, 1].set_title('S2 of Neuron two')
axs[2, 0].plot(state_mon_5.t / br.ms, state_mon_5.v_th1[0])
axs[2, 0].set_title('Threshold neuron one')
axs[2, 1].plot(state_mon_6.t / br.ms, state_mon_6.v_th2[0])
axs[2, 1].set_title('Threshold neuron two')
for i, ax in enumerate(axs.flat):
if i >= 4:
ax.set(xlabel='Time (ms)')
if i%2 == 0:
ax.set(ylabel='Value (au)')
plt.tight_layout()
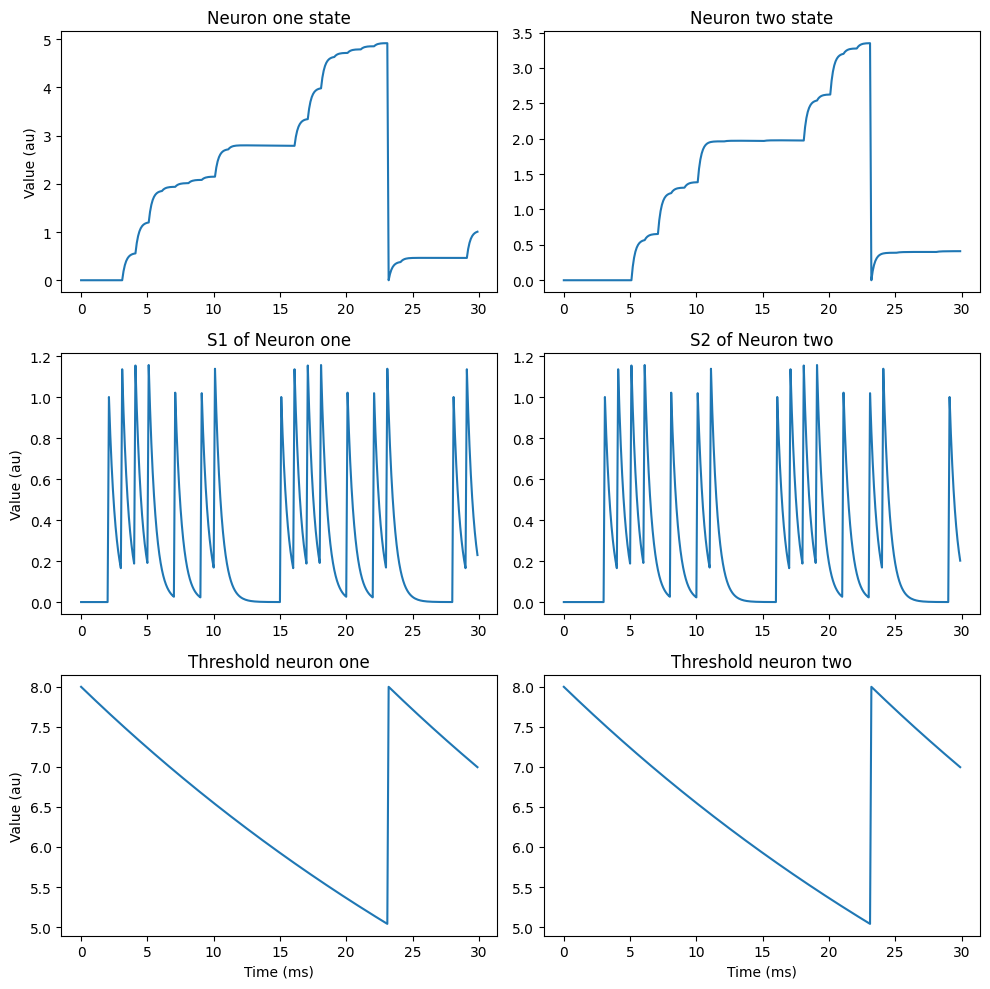
This is just a concept with some initial code. I 80% confident this can work if I found a way to make delays dynamic in brian.
Summary and future prospects¶
I have demonstrated a differentiable delay layer that can be inserted in any architecture for dealy optimization. Also, the effect of tau on learning of a single delay layer is shown. For a single delay layer, it is a non-convex optimization probem, and if the input is stochastic, it is also a stochastic optimization problem. The main challenges for differentiable delays are the form of the synaptic integration function and the loss function.
Depsite the above results, it is still difficult to co-train delays and weights and this needs further investigation. As I mentioned before, cross-entropy might not work well with delays. Maybe we need different loss functions? Lucky guess of the learning rates?
What can be done now?
For single delay layer optimization: we need to study varioius synaptic integration functions, loss functions, the effect of various varaibles, non-convex optimization and stochastic optimization. For a start on stochastic optimzation see: Matsubara (2017)
For co-learning of Delays and Weights: we need two investigate separate loss functions, or another loss function than CE, add some reguarlization terms, investigate the effect of relevant variables (like Learing rate) on performance.
For biologically plausible delay learning: We need to find a way to make delays dynamic during a run in Brian.
As seen from the above points, there is much to do and I would appreciate feedback and cooberation.
Finally, I would like to note that this took tens of hours of me. I don’t mind if anyone would use any part of this code. However, I would appreciate it and be grateful if I am noticed. I am looking for a job and some collaborations :) (when one looking for a home, they are more or less beggers haha). Regardless, anyone can use this code.
- Matsubara, T. (2017). Conduction Delay Learning Model for Unsupervised and Supervised Classification of Spatio-Temporal Spike Patterns. Front. Comput. Neurosci., 11, 104. https://doi.org/10.3389/fncom.2017.00104